


Can LLMs Unlearn? Part 3: The Technical Complexity of it All
This is part of my machine unlearning series. Since it's so long, I have broken this up into sections.

For those of you who are following along, this has been a many months-long quest to discover whether or not large language model (LLM) providers can comply with data subject rights like the right to erasure & the right to be forgotten (RTBF) and whether LLMs generally can unlearn. To make life simpler for everyone, I’ve created some breadcrumbs.
In Part 1, I lay out the problem: LLMs are not databases, and yet our laws expect them to behave like databases. Data protection laws in particular, assume that the things that hold true for databases should be as easy to do for a non-deterministic systems like LLMs. I begin to explain why this is hard.

In Part 2, I start to dig into one reason this is so hard —what I call the ‘underpants gnomes/Which Napoleon’ problem. I ask the key question of how to identify a specific individual within a system in order to erase or correct information about that individual. I also touch on how applying certain tools during the initial training process can help, such as Named Entity Resolution, Named Entity Disambiguation, Linking & Knowledge Graphs, but how that’s also really costly which is probably why no one is doing it.And Part 2 here:

Part 2.5 discusses my ongoing efforts to have OpenAI (and less successfully, Perplexity) forget my data. OpenAI kinda tries, but it never actually erases data about me. It just applies a rather blunt-force hack to the problem. I discuss whether this is sufficient and potential harms from this approach:

In Part 3, I start to explore the research on machine training and unlearning. I define what machine unlearning / forgetting is, and isn’t, and address the techniques researchers have discovered. I also explain why the gold-standard approach of starting with perfect data or full retraining doesn’t scale well, and why other exact unlearning methods are also difficult to do in practice:

Part 4 continues the technical discussion. In this section I touch on approximate unlearning methods, their strengths and limitations. I also discuss adjacent unlearning techniques like differentially private unlearning and federated unlearning:

In Part 5, I will cover the final bits, including suppression methods & guardrails — essentially what OpenAI does to ‘comply’ with data protection laws like the GDPR. I will also close with my thoughts on the state of the law, and how to reconcile the incongruence between technical complexity and legal certainty.
You are here: Part 3 … Data Quality, Retraining & Exact Unlearning techniques.
So now, here we are. I’ve danced around long enough on the preliminaries, now it’s time to dig into the hard stuff. Mainly:
Can LLMs unlearn or forget?
If so, how?
And if they can unlearn or forget, what are the costs, and limitations?
I will break this up into at least a few more parts because at this point, this post alone is close to 50 pages long. No, that is not a typo. The bolded bits are what’s included in this part.
Table of Contents
The necessary assumptions & scope restrictions I’ve had to make in order to make this manageable and not lose my mind.
A short primer (with pictures) on how LLMs work.
A brief discussion of the platonic ideal when it comes to LLM training: starting with pure, uncomplicated, high quality data (and why this probably won’t work)
A primer on machine unlearning (MU) & other methods, with a very strained analogy, and a discussion of their respective limitations and challenges. I discuss:
Exact Machine Unlearning
Approximate Machine Unlearning
Differential Privacy-Based Techniques
Federated Unlearning
Output suppression, Filtering and Text-Classifiers
My conclusions and further thoughts
Given the length, I’ll be breaking this up. Additionally, further posts will discuss why, from a legal perspective, none of these are likely to work for the LLMs we use today, unless someone discovers how to generate the privacy equivalent of a unicorn for data, or if data protection laws change, and importantly, what I think we should do about it.
1. Assumption Time!
Before I go further, I need to lay out the series of assumptions I’ve been making throughout this exercise so we’re all on the same page. Some of these are lifted from Part 2, but some of this is new:
For the purpose of my analysis, I am focused primarily on large language models (LLMs) including multimodal LLMs.1 Essentially, any of the big splashy model families you’ve heard of–ChatGPT, Claude, Gemini, and Meta’s LLaMA, as well as implementations of those models like Perplexity.ai. I say primarily LLMs, but I think most of the analysis & questions can apply to other Deep Neural Networks (DNNs) as well.
In the law, there’s a distinction between erasure/deletion and the right to be forgotten (RTBF). But, for purposes of this part of the analysis, let’s assume that the same techniques can apply to either, probably.
The fundamental premise of erasure and RTBF are grounded in the understanding that personal data, i.e., anything that can ‘identify’ an individual person, like a name, or email address, or anything that makes a person ‘identifiable’ (such as specific physiological or other characteristics) is stored in a structured or findable way–ideally in a database or ‘filing system.’2When EU policymakers drafted the early data protection laws, they were thinking in terms of databases and filing systems–explicit systems for storing and structuring data.3 They were not thinking of records stacked in unstructured piles in a warehouse, the implicit personal information you have about others, or random sticky notes strewn about, even though these types of records often also contain personal data. I suspect that everybody realized that holding the opposite position would make data protection a colossal PITA, and so the policy folks promptly said, “yeah, nah, let’s keep it simple.”4
Policymakers were also not thinking of LLMs, seeing as how they didn’t exist yet.5 But LLMs behave differently than explicit systems like databases or structured filing systems, because they don’t store records–LLMs store the statistical relationships between vectors generated from training data. In the next section, I’ll explain how LLMs work, but understand that this is a very important technical distinction I’m making.Given point 3., I am taking the Hamburg DPA discussion paper position that LLMs do not store or process personal data in the traditional GDPR Article 4 / Recital 26 sense, which is to say that the information contained in the LLM after training cannot be used to identify an individual.6 This is possibly a bit different from California Assembly Bill 1008, which states that personal information can exist in ‘abstract digital formats.’7
However, the training data, inputs and outputs are probably all fair game.
I am assuming that based on how the EU AI Act was written that general purpose AI providers, providers of AI systems, and in some cases, deployers of AI systems which process personal data, must fully comply with the data protection laws, including data subject rights, because those inputs and outputs do constitute processing personal data. However, I will not be digging as much into the law for this post, and that will likely be picked up in a later part of this endless saga.
I am assuming that the focus of regulatory ire will be the foundation model providers, and organizations working with foundational models either as-is, or through fine-tuning. Until things change, I am also assuming that the majority of these models will be trained on large datasets, heavily sourced from the internet, with varying degrees of filtering and data cleansing.
2. How Do LLMs Work?

Ok, I’m going to attempt to explain how LLMs and GPT (Generative Pretrained Transformer) models generally work in a way that should be understandable for everyone. And before anyone asks, yes, I enlisted the help of ChatGPT for this section, mostly to ensure my understanding was expressed in an explainable way. I also relied on Google’s NotebookLM which is amazing for helping to process and reconcile the 50+ papers I reviewed. It is brilliant and I highly recommend using it for complicated research things. Feel free to mock me or get super salty in the comments.
If you don’t want to read all of these words and prefer a video, Three Blue, One Brown’s ‘How Large Language Models Work, a Visual Intro to Transformers,’ is excellent, and extremely informative. I highly recommend it.8
Now then.
LLMs, like Chat GPT, work by analyzing massive amounts of text data, which they use to learn the structure, rules, and patterns of language. Each piece of text is broken down into smaller units called 'tokens,' which consist of whole words, word endings, or fragments. These tokens are stored as numbers, or token ids, which the model uses to interpret relationships of words based on the training data—essentially, which words or fragments typically precede or follow a given another word/fragment. This helps the LLM ‘learn’ the linguistic relationships and patterns in language.
For example, the sentence ‘Carey Lening is a data protection consultant’ is represented in ChatGPT 4o’s brain as this in tokens:
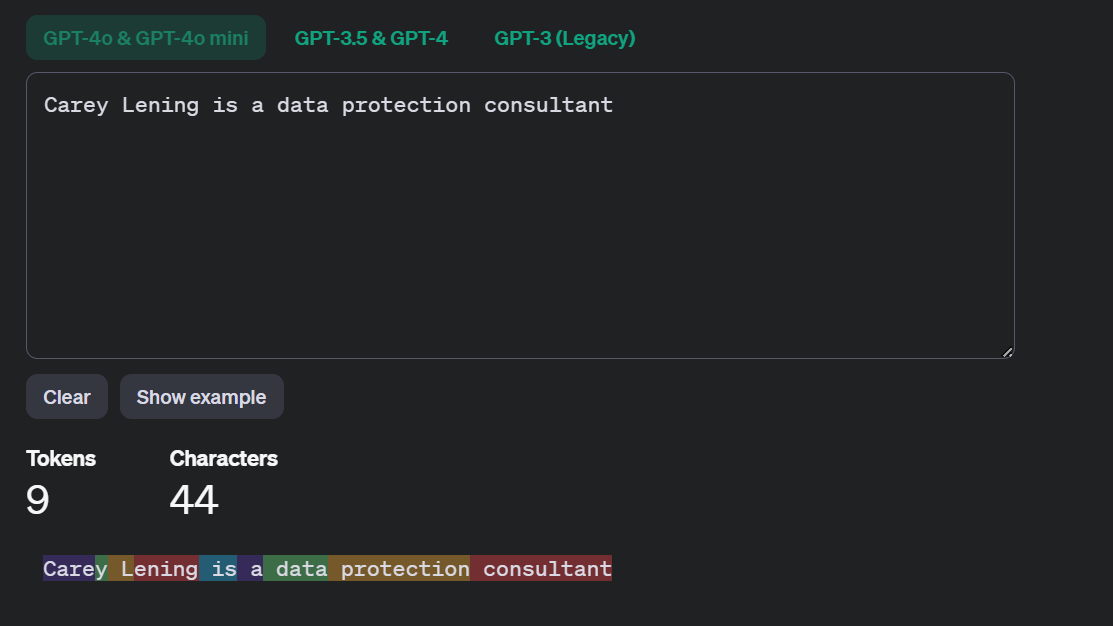
With the following token ids:
[32158, 88, 451, 7299, 382, 261, 1238, 11137, 39198]
And these aren’t fixed token ids! They change between models and providers. Here’s the same sentence for ChatGPT 3.5/4:
[33099, 88, 445, 6147, 374, 264, 828, 9313, 31760]
And here’s how Claude renders the same phrase:
A GPT-based LLM learns how to weigh the relevance of individual tokens to one another via the process of 'self-attention'–in other words, the model learns which tokens to pay attention to (i.e., assign a higher score or weight to) when processing a given sequence of text.9 For example, in the sentence “Carey Lening is a data protection consultant" the model pays more attention to the fragments for 'Lening' when analyzing 'Carey' and assigns a lower score or weight to 'consultant.' By calculating these attention scores, the model builds a representation of the sentence that highlights the most important connections.
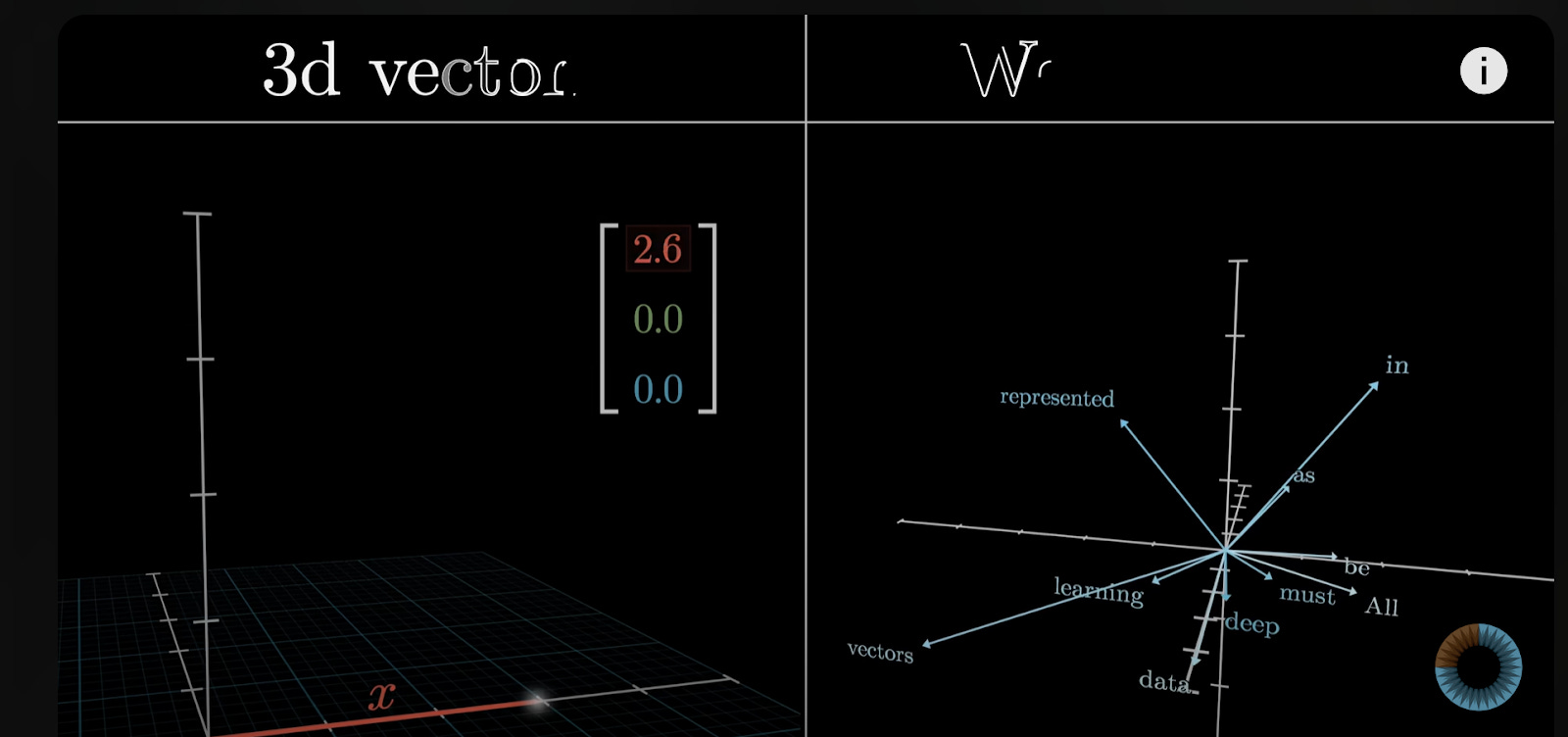
As part of the learning process, tokens are transformed into vectors, through a process called embedding. A vector is a fancy math term which refers to a list (or more accurately, an array) of numbers representing various features of a word. Self-attention relies on three embedding vectors for each token—query, key, and value—which represent different aspects of relationships between tokens.10 This can be graphed in a point in high-dimensional space. Here’s an example from the 3 Blue, 1 Brown video I mentioned earlier:
Models adjust these vectors during training based on various parameters or weights, which influence how the model understands specific parts of language. Parameters are arranged in layers, and each layer learns increasingly abstract features from the specific training data that can be generalized to understand broader patterns. Early parameter layers might focus on simpler patterns, like punctuation or parts of speech, while deeper layers focus on more complex features like tone, theme, or context.
Parameters act like digital knobs, which are adjusted up and down in relation to one another to help the model better understand how strongly each word or phrase should influence the others in a given sentence. So, if I wrote “Carey Lening is a data protection consultant. She lives in Dublin, Ireland, and has nine cats”, context parameters would help the LLM to associate that the word 'she' is referring to 'Carey Lening' and not the cats.
These parameters can be further refined during the process of fine-tuning against specific datasets to prioritize higher-value word combinations within specific domains or contexts, like the legal or medical fields. LLMs have massive numbers of these parameters—GPT-3, for instance, has 175 billion parameters, while Meta’s latest Llama 3.2 model is svelte by comparison–containing between 1 billion and 90 billion parameters.
In essence, an LLM is really just a fancy probability calculator trained on a huge corpus of data. When generating outputs to a prompt, the model doesn’t simply spit out memorized phrases–it constructs new sentences on the fly based on probability and what it has learned about language and the context of the query. Importantly, LLMs don’t know anything about the outputs beyond these vector-based, probabilistic relationships, which is why an LLM can generate entirely bogus, ridiculous, or hallucinated answers to specific questions.
3. Why is this All so Hard?
Before I get into the technical details and various methods of how to effectively do brain surgery on LLMs, it’s worth taking a moment to understand why erasure is hard: the shortest, and simplest answer is of course, GIGO – garbage in, garbage out. The internet is full of lots of hot garbage, and training a LLM on that garbage often leads to garbage outputs. This is complicated by the fact that model creators train their models incrementally, often with new hot internet garbage, and any given update often reflects all the previous updates.11 And don’t even get me started on models that incorporate live web searching.
The second answer is that identifying the specific vector relationships and the parameters that influence them, can be tricky and not always guaranteed. In a way, mucking about with LLMs is a bit like treating a neurological disorder. Even the best experts don’t entirely know which parts of the brain need to be treated, or how drugs might interact with a person’s chemistry or other medications they might be taking, or the precise cross-sections of a brain that need to be surgically removed (while not catastrophically harming the patient). And like brain surgery, getting machines to unlearn (either by retraining them, or getting them to re-calibrate all those vector relationships) is usually very, very costly.
4. Want to Avoid Brain Surgery? Start with Good Data

So right, brain surgery sounds messy. Surely something can be done instead?
The best approach to avoid headaches/surgical intervention down the line is to train a machine learning model appropriately from the beginning and to keep training it appropriately for each new iteration. That means starting with good, well-sourced, known data & having robust data quality practices in place. Good data quality at the most basic level means ensuring that the data used to train the model is accurate, complete, timely, relevant, valid, unique, and consistent.12 In practice this is achieved by:
Ensuring that the model has a defined purpose and isn’t just some generic everything bagel chatbot;
Only training models on data that are necessary to meet the model’s defined purpose(s);
Not training or fine-tuning models on garbage from the internet;
Using licensed data or public domain data (particularly for images, books, news, and other licensable content);
Not including personal data in training or fine-tuning processes—and yes, that probably includes ‘publicly available’ data;13
Training (and retraining) models using a diverse data set and a training methodology that limits biased outputs;
Understanding data lineage (where the training data comes from, and how it has evolved over time) and its provenance (how the data was obtained).
But that doesn’t stop at the initial training stage. Good data quality practices also require ongoing effort. The data itself and training methods must be
Measured: ensuring that existing data continues to meet the defined goals & criteria mentioned above;
Validated: ensuring that data the model is trained on remains necessary, accurate, lawfully collected, complete, current, consistent, unique, and free of bias (to the extent that’s possible);
Well-Governed: ensuring there’s a process in place to accurately measure and validate all that data, and that the measurement and validation processes happen regularly throughout the model’s lifecycle. Governance also includes having training and awareness in place to ensure that the people doing the underlying work know why data quality is important, and auditing models regularly to ensure that bad data doesn’t slip through the cracks.
Training with high-quality, bias-free, and lawfully-obtained data, coupled with high-accuracy measurement, validation & governance processes, particularly for model outputs, means fewer problems and compliance challenges to deal with later. Avoiding training on personal data means controllers are less likely to deal with data subject requests (or defamation actions). Training people on the virtues of data quality helps them to avoid entering personal, copyrighted, proprietary, or illegal data later.
Limitations
All that said, ensuring perfect data quality for LLMs is really, really hard. To get a little religious, it’s like asking that model creators never sin.
Current state-of-the-art neural networks have billions of parameters and ingest terabytes of data in training. You might be able to rigorously apply the steps above on a small, niche model, but I don’t think that the likes of ChatGPT, Gemini, Llama, or anything else trained on the open internet will ever meet the gold-star approach. Even if they wanted to. 14
And I say this not because I think that model developers deserve a free pass. Ensuring that only pristine data goes into any large model usually requires lots, and lots, and lots of time, money, and resources. Data must be hand-curated, cleansed, normalized, labeled properly, and tested to guarantee it remains accurate, unique, and relevant. Training data and outputs must be measured, tested, and reviewed regularly to ensure timeliness, validity, accuracy, and consistency. Also, data ingestion must be hermetic–no new data comes in unless it’s going through all the data quality steps listed above, and absolutely nothing comes in from the wider internet. Perplexity.ai and OpenAI Search will always fail the data quality test.
Finally, all the humans involved (including the users) need to be on the same page. No garbage goes in. No personal data, or copyrighted materials get shared with the chatbot, unless you’re damn sure it dies when the user session does. This approach vastly constrains viable use-cases for LLMs, if not eliminating them entirely. I don’t see how, for example, any chatbot or AI assistant that accepts and stores user inputs could meet these standards because it’s hard to force perfect data quality practices and ensure purity when people unintentionally or intentionallyignore Acceptable Use Policies. This might be more achievable with smaller language models (SLMs) and for ML models that are more fine-tuned for specific use-cases, e.g., models used to filter email or detect and block malware, but those models will never raise eyebrows anyway.
5. Forgetting After the Fact: What’s the State of the Art?
There are many different types of ‘model disgorgement’ or ‘machine unlearning’ techniques that have developed over the last decade.15
The concept of 'model disgorgement' (first introduced by Achillea, et. al., 2023), refers to a broad set of methods focused on eliminating or reducing not just improperly used data, but also the effects of that data on a machine learning model. Disgorgement includes full model retraining, as well as compartmentalization (often referred to as ‘exact unlearning’), and ‘approximate unlearning’ techniques.16
'Machine unlearning' often gets used interchangeably with model disgorgement, though it’s probably more accurate to refer to it when people are discussing approximate unlearning methods specifically, which I’ll discuss below.
Much of the initial machine unlearning/model disgorgement research was inspired by the GDPR’s Right to Be Forgotten obligations, however, many disgorgement and unlearning methods are also widely applicable towards getting LLMs to forget problematic, biased, toxic, infringing, or otherwise harmful information as well.17
A. Exact Unlearning
Retraining & exact unlearning methods like compartmentalization, seek to ensure the complete erasure of unwanted data from a model. These approaches are usually the next best thing to training data properly the first time, because exact unlearning techniques are considered guaranteed and proveable from a computer science perspective. 18
Full Retraining
For LLMs, retraining involves first identifying and removing unwanted data (like, for instance, CSAM) from the training set, potentially adjusting parameters or weights, and then validating that the unwanted data doesn’t pop up somewhere else down the line.
Assuming that the underlying bad data has been completely removed, and the model properly retrained, controllers can meaningfully argue that they meet data protection obligations concerning data minimization, erasure & rectification & the right to object, as well as avoiding infringing on copyright, or violating the law in other ways, at least regarding future processing. 19
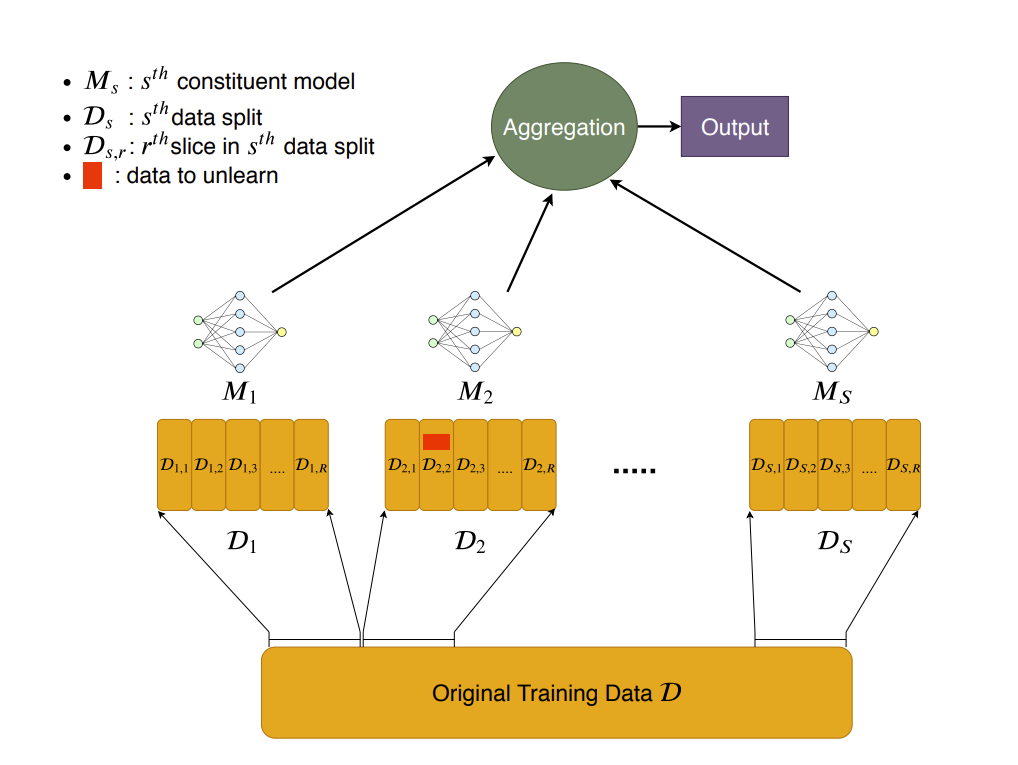
Compartmentalization / SISA
Compartmentalization is functionally similar to retraining, but focuses the retraining only on smaller subsets (or shards) of training data. The state of the art for compartmentalized methods appears to be a technique known as Sharded, Isolated, Sliced, and Aggregated Training, or SISA. SISA involves initially training multiple deep neural networks (DNNs) on different subsets or shards of data in isolation, and then combining and aggregating those shards. SISA facilitates unlearning by allowing developers to selectively retrain only those shards containing unwanted data. 20
Compartmentalization methods are seen as an improvement over full retraining because retraining small shards is far less costly than retraining the whole set, and less damaging to the model overall. Since only a small subset of the model’s ensemble components are modified, the behavior of the new model is more likely to mirror that of the original model, especially if shards are small. If a deletion or rectification request comes in, the model developer only needs to retrain the shard or shards where the underlying data is. IMHO, SISA appears to be the strongest approach (short of full retraining) to meeting legal obligations, but more research will be necessary.21
If you humor me by going back to my brain surgery example for a minute, retraining and exact unlearning approaches like SISA are like moving someone’s brain into a new host body (Altered Carbon-style) where the ‘brain’ in this scenario is the machine learning model, and the body is the training data itself. Unsurprisingly, there are many, many limitations to this approach.
Limitations of Exact Unlearning
Resource Intensive: The challenge with these approaches is that retraining and even exact unlearning methods are expensive computationally and financially and do not scale well.22 In addition to compute and storage costs, retraining and exact unlearning techniques require loads of human capital. Someone (or more accurately, teams of people) need to dig through and find all those relevant vectors and identify the specific training data to remove, and ensure that they aren’t unintentionally grabbing other details.23 As I mentioned in Part 2: Which Napoleon are we talking about here?
Training is costly, which means retraining is also costly. OpenAI shelled out $78 million in compute alone to train GPT-4; Google spent $191 million in compute to train Gemini Ultra.24 I have no idea how many engineering and testing hours went into the retraining process, much less what the total cost or environmental impacts of training were.
Even sharded compartmentalization approaches are expensive and unwieldy when applied beyond the confines of small models and limited datasets. One of the most well-developed exact unlearning approaches, SISA, becomes impractical for large models due to the storage footprint associated with storing multiple model replicas. 25Scaling laws apply. This means that retraining is functionally infeasible to do at an individual request/complaint level, or arguably even in large batches.
Timeliness: The second issue is timeliness. Even if models are retrained in batches every six months, say, this also presents a conundrum under the GDPR and time-bound data protection laws generally: most data subject rights (including access, rectification, & erasure) require controllers to provide information to data subjects and act on their request “without undue delay”26 Is twice a year sufficient? What about once a quarter?
Legally Guaranteed? While exact methods are considered by computer scientists to be guaranteed,27 it’s possible that the law may not always agree, especially if a model outputs something that looks suspiciously like the unwanted data alleged to have been erased. For example, one research team noted (in the context of another machine unlearning method)28 that the gold standard of retraining may still lead to errors and the unwanted values may still surface in the results.
As I have lamented in the past, the data protection laws are generally silent on the question of technical complexity. The best argument a LLM provider could make is that it is “not in a position to identify the data subject” any longer after retraining. 29Will that hold? I don’t know.
Requires Access to Training Data: Retraining and exact unlearning require access to the training data. In other words, this might be an option for Meta, OpenAI, or Google, but if your fancy LLM is merely built on those models, you’re probably SOL.
Model Quality: Finally, there are model quality issues to consider. Exact unlearning methods may impact model biases, fairness, and accuracy, and it is almost entirely impossible for models incorporating live search or current events data.
In the context of compartmentalization approaches, shard size matters30. If the shards are too small, it may lead to poor model performance and reduce unlearning efficiency. There’s also a potential for information leakage between shards if they aren’t properly isolated, which ultimately requires that the model providers know which shards the data reside in.31
Wewh. That’s enough for one post, but don’t worry, there’s more. So much more. Until then:
A multimodal LLM is a large language model capable of processing multiple types of inputs or data—such as text, sound, images, videos, and more.
See: Article 2(1) GDPR and Article 4(1) and (2) GDPR.
I had an earlier bit about deterministic / non-deterministic systems and over the course of all this research (and many, many, many consultations with Husbot), I have changed how I refer to this distinction. He suggested the idea of explicit vs. implicit systems. A database is explicit, in the sense that you can make a query for a specific record and retrieve that record as an output. An implicit system is more like trying to find a particular file that contains the details of John Smith, buried in a pile a mile high in your office. That record exists, and maybe it’s findable, but there’s no direct or clear way of getting access to it.
This point is specifically called out in Recital 15 GDPR. “... Files or sets of files, as well as their cover pages, which are not structured according to specific criteria should not fall within the scope of this Regulation.”
Rights to have one’s data deleted or erased go back to at least the 1970s in some jurisdictions, including the UK and Germany, and were hinted at in the US going back to the 30s and 40s.
The RTBF is newer, and was only really formalized by the EU Court of Justice in the 2014 Google Spain decision. See: Google Spain SL, Google Inc. v Agencia Española de Protección de Datos, Mario Costeja González, C-131/12, ECLI:EU:C:2014:317.
The Hamburg Commissioner for Data protection and freedom of information, Discussion Paper: Large Language Models and Personal Data (2024) at: https://datenschutz-hamburg.de/fileadmin/user_upload/HmbBfDI/Datenschutz/Informationen/240715_Discussion_Paper_Hamburg_DPA_KI_Models.pdf. I am mindful that this is a discussion paper and not regulatory guidance. According to the European Data Protection Board we should be receiving some guidance by the end of the year. Fingers crossed.
See: California AB 1008, An act to amend Section 1798.140 of the CIvil Code, relating to privacy. https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=202320240AB1008.
Madhi Assan also has a great accessible explainer on how LLMs work on his Substack,
. Do LLMs store personal data? It’s worth a read.The whole GPT revolution was kicked off in 2023 when researchers from Google and the University of Toronto released Attention is All You Need, which explained the self-attention concept in relation to a new ‘Transformer’ model, which is the approach taken by most LLMs. Ashish Vaswani et al., Attention Is All You Need, arXiv.org (2017), https://arxiv.org/abs/1706.03762 (last visited Nov 8, 2024).
For details on query, key, and value elements, as well as more on the self-attention processes generally, see: Yesha Shastri, Attention Mechanism in LLMs: An Intuitive Explanation, DataCamp, Apr. 26, 2024, https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition (last visited Nov 8, 2024).
See: Lucas Bourtoule et al., Machine Unlearning, in 2021 IEEE Symposium on Security and Privacy (SP) (2021), http://dx.doi.org/10.1109/sp40001.2021.00019 (last visited Oct 29, 2024).
The Data Management Association (DAMA) nerds call these ‘data quality dimensions’, and identify the six I listed above. But there are loads of other types of data quality dimensions, metrics, or criteria, shilled by various vendors, data quality experts & organizations, and I would rather die than be bothered going into a long digression on that.
I say probably, because jurisdictions differ on what is considered public, and even the Court of Justice only recently sorted this one out. See: Maximilian Schrems v Meta Platforms Ireland Limited, C-446/21, ECLI:EU:C:2024:834. For what it’s worth, OpenAI notes in the model card for o1 that it is applying at least some filtering and refinement techniques in its data processing pipeline, including “advanced data filtering processes to reduce personal information from training data. We also employ a combination of our Moderation API and safety classifiers to prevent the use of harmful or sensitive content, including explicit materials such as CSAM.”
Though I’m pretty sure they don’t, because $$$.
The term ‘machine unlearning’ was first coined by Yinzhi Cao and Junfeng Yang in their 2015 paper, Towards Making Systems Forget with Machine Unlearning, in 2015 IEEE Symposium on Security and Privacy 463 (2015), http://dx.doi.org/10.1109/sp.2015.35 (last visited Oct 30, 2024).
Varun Gupta et al., Adaptive Machine Unlearning, 34 Advances in Neural Information Processing Systems 16319 (2021). https://proceedings.neurips.cc/paper_files/paper/2021/file/87f7ee4fdb57bdfd52179947211b7ebb-Paper.pdf (last visited November 8, 2024)
Alessandro Achille et al., AI Model Disgorgement: Methods and Choices, 121 Proceedings of the National Academy of Sciences (April 2024). https://doi.org/10.1073/pnas.2307304121 (last visited October 29, 2024).
Id.
Which is to say, the retrained model will only apply to subsequent versions.
See: Machine unlearning. This approach has been referred to by other researchers as Compartmentalization through a mixture of experts (MoE) approach. See also: AI model disgorgement: Methods and Choices.
I am not the only one who thinks this is the case. See: Ken Ziyu Liu’s Machine Unlearning in 2024 (last visited October 28, 2024).
See: Machine Unlearning; Jin Yao et al., Machine Unlearning of Pre-Trained Large Language Models, in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 8403 (2024), http://dx.doi.org/10.18653/v1/2024.acl-long.457 (last visited Nov 9, 2024).
Youyang Qu et al., Learn to Unlearn: Insights Into Machine Unlearning, 57 Computer 79 (March 2024). DOI: 10.1109/MC.2023.3333319 (last visited October 29, 2024).
Stanford University Human-Centered Artificial Intelligence, AI Index Report 2024 – Artificial Intelligence Index, S, https://aiindex.stanford.edu/report/ (last visited Nov 8, 2024).
See: Machine Unlearning of Pre-Trained Large Language Models. SISA is also one of the few models that provides privacy-focused guarantees. See also: Guihong Li, et al. Machine unlearning for image-to-image generative models. arXiv preprint (2024). https://doi.org/10.48550/arXiv.2402.00351 (last accessed October 29, 2024).
See: Articles 16-17 GDPR; Recital 59 GDPR.
See: AI model disgorgement: Methods and Choices. Approaches like compartmentalization ensure “by construction that the disgorged data will have zero influence on the disgorged model.” But see: Anvith Thudi et al., On the Necessity of Auditable Algorithmic Definitions for Machine Unlearning, arXiv.org (2021), https://arxiv.org/abs/2110.11891 (last accessed Nov 2, 2024).
Id; Aditya Golatkar, et. al,, Eternal Sunshine of the Spotless Net: Selective Forgetting in Deep Networks, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 9301 (2020), http://dx.doi.org/10.1109/cvpr42600.2020.00932 (last visited Oct 29, 2024).
Article 11(2) GDPR:
Where, in cases referred to in paragraph 1 of this Article, the controller is able to demonstrate that it is not in a position to identify the data subject, the controller shall inform the data subject accordingly, if possible. 2In such cases, Articles 15 to 20 shall not apply except where the data subject, for the purpose of exercising his or her rights under those articles, provides additional information enabling his or her identification.
Id.