
Can LLMs Unlearn? Part 4: The Technical Complexity of it All (continued)
In this section, I discuss approximate unlearning, differential privacy & federated learning techniques for unlearning
For those of you who are following along, this has been a many months-long quest to discover whether or not large language model (LLM) providers can comply with data subject rights like the right to erasure & the right to be forgotten (RTBF) and whether LLMs generally can unlearn. To make life simpler for everyone, I’ve created some breadcrumbs.
In Part 1, I lay out the problem: LLMs are not databases, and yet our laws expect them to behave like databases. Data protection laws in particular, assume that the things that hold true for databases should be as easy to do for a non-deterministic systems like LLMs. I begin to explain why this is hard.

In Part 2, I start to dig into one reason this is so hard —what I call the ‘underpants gnomes/Which Napoleon’ problem. I ask the key question of how to identify a specific individual within a system in order to erase or correct information about that individual. I also touch on how applying certain tools during the initial training process can help, such as Named Entity Resolution, Named Entity Disambiguation, Linking & Knowledge Graphs, but how that’s also really costly which is probably why no one is doing it.And Part 2 here:

Part 2.5 discusses my ongoing efforts to have OpenAI (and less successfully, Perplexity) forget my data. OpenAI kinda tries, but it never actually erases data about me. It just applies a rather blunt-force hack to the problem. I discuss whether this is sufficient and potential harms from this approach:

In Part 3, I start to explore the research on machine training and unlearning. I define what machine unlearning / forgetting is, and isn’t, and address the techniques researchers have discovered. I also explain why the gold-standard approach of starting with perfect data or full retraining doesn’t scale well, and why other exact unlearning methods are also difficult to do in practice:

Part 4 continues the technical discussion. In this section I touch on approximate unlearning methods, their strengths and limitations. I also discuss adjacent unlearning techniques like differentially private unlearning and federated unlearning:

In Part 5, I will cover the final bits, including suppression methods & guardrails — essentially what OpenAI does to ‘comply’ with data protection laws like the GDPR. I will also close with my thoughts on the state of the law, and how to reconcile the incongruence between technical complexity and legal certainty.
You are here: Part 4 … Approximate Unlearning, Differentially Private & Federated Unlearning
Bolded bits are in this section
Table of Contents
The necessary assumptions & scope restrictions I’ve had to make in order to make this manageable and not lose my mind.
A short primer (with pictures) on how LLMs work.
A brief discussion of the platonic ideal when it comes to LLM training: starting with pure, uncomplicated, high quality data (and why this probably won’t work)
A primer on machine unlearning (MU) & other methods, with a very strained analogy, and a discussion of their respective limitations and challenges. I discuss:
Exact Machine Unlearning
Approximate Machine Unlearning
Differential Privacy-Based Techniques
Federated Unlearning
Output suppression, Filtering and Text-Classifiers
My conclusions and further thoughts
Given the length, I’ll be breaking this up. Additionally, further posts will discuss why, from a legal perspective, none of these are likely to work for the LLMs we use today, unless someone discovers how to generate the privacy equivalent of a unicorn for data, or if data protection laws change, and importantly, what I think we should do about it.
B. Approximate Unlearning Techniques
In contrast to exact unlearning, approximate unlearning techniques focus on modifying the parameters, weights, and inferences or behaviors made by an LLM. Importantly, approximate unlearning methods do not require retraining, and some methods can be actualized without requiring access to the model training data and/or weights.
Say, a model has learned that the phrase ‘Carey Lening _____’ is highly weighted to be followed by the word ‘loves cats’, or ‘drinks beer’, or ‘is easily fascinated with cheese.’ Approximate techniques can be used to ‘preturb’ (or influence) the likelihood that these phrases appear in proximity to each other, and instead link those words to a different word or phrase, such as ‘loves Harry Potter’, or ‘hates drinking’, or ‘hates cheese’. Here’s a good example using image data:
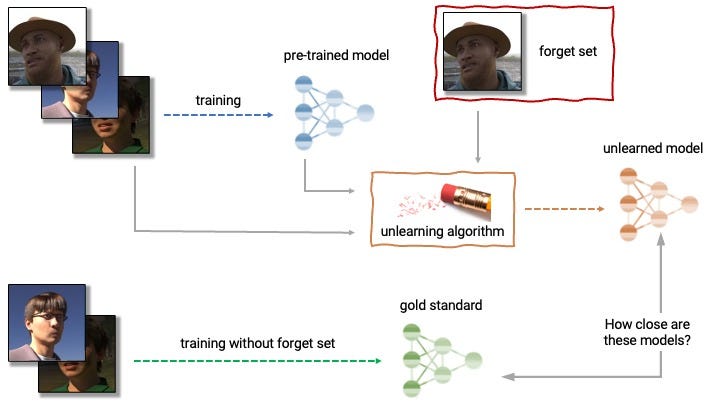
While the research itself is varied, to strain my neurology analogy, the techniques range from the ML equivalent of brain surgery, to the use of prescription drugs, brainwashing1, or the use of hypnosis or mind-altering experiences.
I have attempted to wrangle this extremely broad category into a few smaller groups because nobody wants to read 300+ papers. But if you do, because you’re really interested in unlearning or a masochist, I have included a sheet of the available literature as of November 2024.2
Most of the machine unlearning techniques regardless of flavor, focus on selectively removing or altering some unwanted samples (commonly referred to as the 'forget set') while minimizing any adverse effects on the performance of the remaining data (the 'retain/remember set'). These forget/retain set concepts frequently appear in the literature as 𝒟f (forget set) and 𝒟r (retain/remember set). I won’t be applying much math in this post, but if you follow any of the links to various papers, you’ll see these terms pop up a lot.
1. Brain Surgery Approaches
Gradient-Based Unlearning
Gradient-based unlearning approaches aim to adjust a model’s parameters or weights in a way that selectively removes the influence of specific data points or patterns, usually by adjusting what is known as the model’s ‘loss function.’3 A loss function measures the discrepancy between the model's predictions and the actual target values, usually over the whole training set.
There are two different gradient-based approaches: gradient ascent and gradient descent. These techniques apply an optimization algorithm that moves in the direction of increasing loss either backwards (gradient ascent) or forwards (gradient descent) in order to unlearn data.4 This effectively pushes the model’s associations away from the data to be forgotten in each respective direction. In other words, it changes what data is considered important to the model. Sometimes, both methods are employed together in the unlearning process.5
Selective Forgetting / Scrubbing
Taking a page from the movie Eternal Sunshine of the Spotless Mind, some researchers have proposed the idea of selectively forgetting or scrubbing particular information located in a training set.6 The exact process involves modifying relevant weights so that any probing function of the weights is indistinguishable from those applied to the weights of a network trained without the forget-set data.
For example, if Bob Smith in Akron, OH asks to be forgotten, applying a selective forgetting approach would mean that a query of ‘Who is Bob Smith’ might yield a different result instead.
2. Pharmaceutical Approaches
Bayesian Unlearning
This method uses Bayesian statistical methods to update the probability outcomes of model parameters. The goal is to remove the influence of specific data, from the model’s updated parameters and associated probabilities from the training data, as if the original training data never included the deleted data in the first place.7
Representation-Based Unlearning
A more recent approach, referred to as Representation Misdirection for Unlearning (RMU) or Representation-Based Unlearning focuses on perturbing the model's internal activations on hazardous data while preserving activations on benign data. Inspired by representation engineering, these techniques focus on manipulating how LLMs ‘understand’ or process information or concepts learned by the model.8 The idea is that by modifying these representations, developers can control the model's behavior to remove the influence of the forgotten data. For example, some research has focused on getting machines to modify their representations of harmful or hazardous data while preserving activations on benign data.9
I liken these to drug-based approaches because it’s more about changing how the brain/ML model processes or represents data–akin to say, how a drug might alter chemical signals going to the brain.
3. Brainwashing Methods
Model Editing & Fine-Tuning with Random Labels
Another unlearning approach is known as knowledge or model editing.10 Model editing involves replacing inaccurate or obsolete information, categories, or behaviors from the forget set with new information. This differs from other types of machine learning because model editing is about replacing or correcting unwanted references and behaviors rather than erasing or eliminating information entirely.11
Techniques MEMIT and Knowledge Editing modify specific model weights associated with certain knowledge or ‘memories’, effectively making the model 'forget' specific information without retraining from scratch.12
Fine-tuning with random labels is similar, but instead of specifying specific model replacement variables as with model editing, the random labels approach involves, unsurprisingly –random labels. This aims to obfuscate the model's knowledge of the forgotten data.13
Extra Learnable Layers
This approach involves applying additional training layers to a model specifically designed to forget different sets of data (such as personal data contained in an erasure request).14 These layers are trained to counteract the influence of the data to be forgotten, while preserving the model's performance on the remaining data. Some of these approaches also incorporate SISA sharding for improved efficiency and utility guarantees.15 However, if the layers are ever removed, the model reverts to its original behavior/memories.16
Knowledge Distillation
Knowledge distillation approaches apply a teacher-student model where the teacher LLM attempts to guide a student model to provide only retain-set data or to generate other non-harmful responses instead.17
Dataset Emulation
Dataset emulation attempts to address privacy-related issues in machine learning by substituting real data with synthetic data.18 The substitution processes are designed in a way to achieve the general properties of the real data without exposing information about real individuals. Synthetic data generation is a much-talked about approach to solving many privacy challenges, but applications still remain very isolated and specific. It’s more commonly applied to images versus text data. Here’s an example using image data.

4. Hypnosis & Mind-Altering Drugs?
Researchers have also tested various methods of getting machines to unlearn by tweaking their user-based inputs and generated outputs. So, instead of mucking around with the internals (either the training data, or the weights/parameters) directly, they apply post-hoc modifications, usually through specialized prompts.
Adversarial Unlearning
One method relies on adversarial attacks which use specially-crafted inputs that are similar to the forget set and designed to fool a model to unlearn data.19 By training the model via input prompts to misclassify these adversarial samples, the influence of the forget set data can be reduced, though not eliminated. The various adversarial techniques are unique in that they represent one of the few methods that do not always require access to model weights or training data.
In-Context Learning
Another approach is in-context learning, where an LLM creates a “memory” of recorded cases where the model has previously misunderstood user intent or, presumably, generated a harmful or unwanted result.20 A “correct” or acceptable response is provided in its place, presumably by the model developer. This allows new prompts that match or are similar to the recorded pattern can then be replaced with the desired result.
The only real way I can explain this in my now completely fractured analogy is that these techniques are akin to hypnosis. Or maybe similar to the effects of a really profound acid trip. I don’t know. I haven’t done acid. But they aren’t exactly brainwashing, and I don’t have a better classification, so if you do, let me know.
C. Differential Privacy-Based Techniques
Another category of unlearning relies on differentially private techniques. Differentially private (DP) techniques focus on guaranteeing that unique data within the training set do not end up in the model’s final parameters where they might leak information about an individual.21 Roughly, an algorithm (or ML model) is considered differentially private if an observer seeing its output cannot tell whether a particular individual's information was used in the computation.22
Most ML DP techniques apply approaches from the larger field of differential privacy to proactively train (as opposed to retroactively modify) ML models in a way that offers greater mathematical certainty that no single piece of information has more than a negligible effect on the output generated. This is achieved by adding a large amount of noise (or synthetic data), to ‘preturb’ the model. Think of it like adding static to a recording of many people talking so that it’s hard to pick out any single voice.
But there’s a balance to be struck: Too much noise, and the model risks becoming worthless or ceases the ability to learn. Too little, and it no longer protects user privacy. The goal (as with all DP implementations), is to add just enough noise to achieve the outcome desired (e.g., not sharing personal data) while avoiding adding so much noise that the model is degraded. This should hold even for adversaries with access to the model's internal parameters.
I need to take a pause and admit that when I’ve reviewed the literature on DP techniques for unlearning, most of what came back was … fancy math and variations of the description I mention above (primarily in survey papers).23 Unlike the more specific approximate unlearning methods, DP research focuses on implementing privacy in the training set (which IMHO, is closer to starting with good data), or as a method for testing or evaluating the efficacy of other unlearning models.
Limitations of Approximate Unlearning & Differential Privacy Techniques
No Guarantees: Due to the stochastic nature of how LLMs work, and the difficulty in specifying what to unlearn in some cases, approximate methods cannot guarantee that information in the forget set is completely removed in model weights, much less the data or parameters themselves. At best, these approaches offer a strong probability that the offending/erased data is forgotten in some sense.24 Whether that is legally sufficient is a separate question.25 The same questions arise outside of data protection as well, including for copyright.
Accuracy Issues: In the context of data protection, brainwashing and approaches that ‘trick’ the model into providing bogus answers raise interesting challenges of their own. Given obligations to ensure accuracy and completeness of data under Article 5(1)(d), these approaches seem to … violate that obligation? Sure, the problematic data about Bob Smith may be forgotten but it’s replaced with inaccurate data. Reconciling data subject rights with the larger principles of data protection will require more analysis.
Auditability: In relation to most of the techniques listed above, one is right to ask: if the underlying training data itself is never touched, does this even count as erasure under the law?26 While removing associated weights that might link 'Bob' and 'Smith' together would arguably meet the spirit of RTBF, the data itself surely cannot be said to be erased.
Separately, how does the model developer even test whether the personal data in the forget set is actually forgotten?27 And what about providers like Perplexity that use other LLMs for their own products? No doubt, there will be a thriving market for auditing and testing platforms to address this market need.28
Risk of Unintended Consequences: A related concern is the larger issue of the unintended consequences of forgetting one set of information with regard to other data. For methods focused on surgical or drug-altering approaches like gradient-based unlearning, tinkering may end up accidentally penalizing correct/true/desirable outputs that are perfectly legitimate.
A repeatedly mentioned risk in the literature is one of catastrophic forgetting,29 which risks degrading a model’s performance beyond the target content to forget, including benign, public domain or factual details. For example, Microsoft applied a machine unlearning model which successfully persuaded Meta’s Llama-7b-chat-hf model to forget copyrighted content from the Harry Potter universe.30 They discovered however, that this approach may lead models to forget or refuse to provide other information such as general, factual knowledge related to Harry Potter well outside of copyright protection. This could have profound impacts on fair use and sharing legitimate information or generating new works from LLMs.
In the context of data protection, this can have similar impacts on individuals who should not or do not want to be forgotten. If Ted Bundy, the reflexologist in London seeks to have OpenAI erase his data, what happens to further searches of Ted Bundy (the serial killer) on ChatGPT?
The underspecification of unlearning requests, particularly in the context of personal data (but also other types of data, such as ‘toxic’ content), introduces a new complication: we now have to deal with defining 'unlearning scope' (or 'editing scope') and 'entailment'. As Ken Ziyu Liu explains
unlearning requests may provide canonical examples to indicate what to unlearn, but the same information can manifest in the (pre-)training set in many different forms with many different downstream implications such that simply achieving unlearning on these examples—even exactly—would not suffice.31
Bias and Fairness: Another issue related to many approximate techniques, including DP techniques, is that these approaches may unintentionally introduce bias. For many LLMs some domains are represented by a small number of very important data points. For example, health data related to rare diseases, or the corpus of materials written in the Xhosa language (Isixhosa) on the internet.
Since these data points are highly influential for defining the behavior of the model,32 they carry the risk of identifiability of individuals, or in the case of Isixhosa texts, may still be under copyright. Since it’s arguably impossible to add noise to something like a language or a rare disease, the best approach would be to not include those sources at all. But excluding Isixhosa data (or rare disease data) from a language or ML model further biases the model to be weighted towards content that is already more widely represented (i.e., English-language texts or more common diseases).
Difficulty Generating Synthetic Data: For techniques that rely on the generation of synthetic data, such as data emulation, generating robust synthetic data that can act as a viable substitute for the real data is not always straightforward. It’s relatively easy to say, generate synthetic or dummy phone numbers; much harder to identify and create synthetic representations of inferrable personal characteristics, facial images, or unstructured text in a way that doesn’t compromise the utility of the model itself. 33
Identification Complexity: The complexity of large-scale deep neural networks also makes identifying the relevant weights or parameters hard to identify and assess. Knowing what to take out, or which weight to tweak is a wicked problem. Unsurprisingly, there is active research34 in this area and dedicated benchmarking tools35 for assessing various machine unlearning techniques:
TOFU: TOFU (Task of Fictitious Unlearning for LLMs) is a benchmarking tool that assesses the effectiveness of different unlearning techniques for unlearning individuals that uses synthetically-generated book authors and information as a dataset.
WMDP: WMDP (Weapons of Mass Destruction Proxy) is a dataset of 3,600+ multiple-choice questions focusing on testing unlearning methods related to dangerous knowledge, specifically on biosecurity, cybersecurity, and chemical security. WMDP serves as both a proxy evaluation for hazardous knowledge in LLMs and a benchmarking tool for unlearning methods to remove such knowledge.
MUFAC and MUCAC: MUFAC (Machine Unlearning for Facial Age Classifier) and MUCAC (Machine Unlearning for Celebrity Attribute Classifier) are two datasets used to evaluate the performance and robustness of machine unlearning algorithms concerning image data.
Feasibility: Many unlearning techniques, as well as those which apply differentially private approaches, are highly contextual to specific model families or use-cases,36 or they require access to, and validation against the original and re-trained datasets or model weights (aka, “white-box” access), which limit their utility and feasibility in most real-world contexts.
Almost all of these techniques, bar in-context unlearning and adversarial unlearning, must be applied by the foundational model developers. Downstream deployers or providers of AI systems relying on someone else’s training data or model weights likely are out of luck.
Vulnerability to Attack: There’s a separate and fascinating area of research related to privacy leakage, data poisoning, and membership inference attacks (MIAs) that focus on methods to exploit unlearning techniques.37 I am already running long on this, so I won’t go into much detail here, but MIAs are methods that allow an attacker to infer whether a particular subset of data was used in the initial training set (i.e., that it belongs in the ‘forget set’), particularly about an individual or an image, based on comparing the original model with a retrained version.38
In the next installment, I’ll talk about Federated Learning, output suppression, filtering & text-based classifiers, their respective limitations, and some overall conclusions about where we are. Stay tuned!
While I had arrived at the brain surgery analogy independently, I’ve got to give credit to Ben Luria of Hirundo for the ‘brainwashing’ example. I was thinking only of surgery and drugs
Google Sheets link is here. This is mostly based on two great github resources, Machine Unlearning Papers by jjbrophy47 and tamlhp’s Awesome-Machine-Unlearning repositories. I have done some consolidation, de-duplication and gap-filling, but these two did all the actual work and I have cited them accordingly.
See: Machine Unlearning in Generative AI: A Survey, Sec. 4.1.2 for all the different variations of gradient-based approaches.
See: Machine Unlearning in Generative AI, for information, Sec. 4.1.2 generally, including all the citations for gradient ascent and descent techniques. There are so, so many. See also my Google sheet for up-to-date literature.
See: Jin Yao et al., Machine Unlearning of Pre-Trained Large Language Models, in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 8403 (2024), http://dx.doi.org/10.18653/v1/2024.acl-long.457 (last visited Nov 11, 2024).
Q. P. Nguyen, et al., Variational bayesian un-learning, Advances in Neural Information Processing Systems, vol. 33,pp. 16 025–16 036 (2020); Ambrish Rawat, et al., Challenges and Pitfalls of Bayesian Unlearning, Workshop, International Conference on Machine Learning (ICML) 2022, arXiv:2207.03227. (last accessed October 30, 2024)
See: Izzy Barrass, Representation Engineering: a New Way of Understanding Models, Center for AI Safety, April 2024 at: https://www.safe.ai/blog/representation-engineering-a-new-way-of-understanding-models (last accessed Nov 11, 2024). This original work was applied to assessing an LLM’s conception of ‘honesty’. It remains an open question on whether this can be applied to something more granular like a RTBF request.
See: Nathaniel Li et al., The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning, arXiv.org (2024), https://arxiv.org/abs/2403.03218 (last visited Nov 12, 2024).
Hirundo is, to my knowledge, the only company applying model/knowledge editing, or any machine unlearning process in an applied way. They have a fairly accessible video explaining more about the process and model editing, and how it differs from retraining and other unlearning methods.
See: Zheyuan Liu et al., Machine Unlearning in Generative AI: A Survey, arXiv.org (2024), https://arxiv.org/abs/2407.20516 (last visited Nov 11, 2024).
On Model Editing and MEMIT, Kevin Meng., et al. Mass-Editing Memory in a Transformer, arXiv preprint (2022) at: https://arxiv.org/abs/2210.07229; On Knowledge editing, see: Eric Mitchell, et al., Memory-Based Model Editing at Scale, Proceedings of the 39th International Conference on Machine Learning, Baltimore, Maryland, USA, PMLR 162 (2022) https://proceedings.mlr.press/v162/mitchell22a/mitchell22a.pdf (last visited Nov 11 2024).
See: Machine Unlearning in Generative AI, Sec. 4.1.5; Jiaao Chen & Diyi Yang, Unlearn What You Want to Forget: Efficient Unlearning for LLMs, in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing 12041 (2023), http://dx.doi.org/10.18653/v1/2023.emnlp-main.738 (last visited Oct 30, 2024).
See: Vinayshekhar Bannihatti Kumar, et. al., Privacy Adhering Machine Un-Learning in NLP, in Findings of the Association for Computational Linguistics: IJCNLP-AACL 2023 (Findings) 268 (2023), http://dx.doi.org/10.18653/v1/2023.findings-ijcnlp.25 (last visited Oct 30, 2024).
Blanco-Justicia, et al., Digital Forgetting in Large Language Models: A Survey of Unlearning Methods, arXiv:2404.02062v1 [cs.CR] (2024) at: https://arxiv.org/pdf/2404.02062 (last accessed Nov 11, 2024).
See: Id. Also: Lingzhi Wang et al., KGA: A General Machine Unlearning Framework Based on Knowledge Gap Alignment, in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 13264 (2023). http://dx.doi.org/10.18653/v1/2023.acl-long.740 (last visited Oct 30, 2024); Yijang Dong, et. al, Unmemorization in Large Language Models via Self-Distillation and Deliberate Imagination. arXiv preprint arXiv:2402.10052 (2024). https://doi.org/10.48550/arXiv.2402.10052 (last visited Oct 30, 2024).
AI model disgorgement: Methods and Choices. This paper, in addition to identifying other methods and providing a classification goes into the most depth on the dataset emulation process.
See: Chenxu Zhao, et al., Rethinking Adversarial Robustness in the Context of the Right to be Forgotten. Proceedings of the 41st International Conference on Machine Learning, PMLR 235:60927-60939 (2024). https://proceedings.mlr.press/v235/zhao24k.html (last visited Nov 11, 2024); Sungmin Cha et al., Learning to Unlearn: Instance-Wise Unlearning for Pre-Trained Classifiers, 38 Proceedings of the AAAI Conference on Artificial Intelligence 11186 (2024) at: https://arxiv.org/abs/2301.11578 (last visited Nov 11, 2024); Digital Forgetting in Large Language Models.
See: Digital Forgetting in Large Language Models; Aman Madaan et al., Memory-Assisted Prompt Editing to Improve GPT-3 after Deployment, in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (2022), http://dx.doi.org/10.18653/v1/2022.emnlp-main.183 (last visited Nov 11, 2024); Machine Unlearning in Generative AI, Sec.4.2.1.
Machine Unlearning in 2024, Sec. 2.2.
“Differential Privacy” Wikipedia.
See: Machine Unlearning in 2024, Sec. 2.2; Ayush Sekhari et al., Remember What You Want to Forget: Algorithms for Machine Unlearning, arXiv.org (2021), https://arxiv.org/abs/2103.03279 (last visited Nov 12, 2024).
Machine Unlearning in 2024, Sec. 2.2
Shameless plug: I’m happy to consult on this.
See: Zheyuan Liu et al., Towards Safer Large Language Models through Machine Unlearning, in Findings of the Association for Computational Linguistics ACL 2024 1817 (2024), http://dx.doi.org/10.18653/v1/2024.findings-acl.107 (last visited Oct 30, 2024).
Ronen Eldan & Mark Russinovich, Who’s Harry Potter? Approximate Unlearning in LLMs, arXiv.org (2023), https://arxiv.org/abs/2310.02238 (last visited Nov 13, 2024).
Machine Unlearning in 2024, Sec. 2.4
Id.
Id.
Id., Sec 3. Sec. 3 discusses this more fully.
Pratiksha Thaker, Yash Maurya, Guardrail Baselines for Unlearning in LLMs (2024). arXiv preprint (last visited Nov 2, 2024).
Most researchers apply this to small image-based datasets, not text.
See: Janvi Thakkar, Giulio Zizzo, et al., Differentially Private and Adversarially Robust Machine Learning: An Empirical Evaluation, arXiv:2401.10405v1 [cs.LG] 18 Jan 2024,
M. Chen, Z. Zhang, et al., When Machine Unlearning Jeopardizes Privacy. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS ’21), November 15–19, 2021; R. Shokri, M. Stronati, et. al., Membership inference attacks against machine learning models. 2017 IEEE symposium on security and privacy (SP). pp. 3–18. IEEE (2017); N. Carlini, S. Chien, Membership Inference Attacks From First Principles. arXiv:2112.03570v2 [cs.CR] 12 Apr 2022.
Since this article is already getting insane, I’m not going to dig too deeply into various adversarial attack methods, but the paper cited does a good job explaining the process.