
The Ladder to Nowhere: How OpenAI Plans to Learn Everything About You
ChatGPT Health is a small part of a much larger plan to learn everything about you.
Some housekeeping:
This is a very long post. So long that a friend suggested I break it up, and she is wise, and I agree. But these words are necessary. This isn’t a short-form kind of piece, and there is a lot to unpack. There are 6 sections. This post will cover Sections 1-3, and there’s a bunch of funny memes at the end.
I have turned paid subscriptions back on (to juke the Substack Algorithm). If you want to become a paid subscriber, awesome. I have some nice incentives for paid subscribers. But if you don’t, that’s absolutely fine. This post will remain free, because what I’m saying here affects all of us, and shouldn’t be buried behind a paywall.
I want you to take a minute and visualize yourself climbing a long ladder. The ladder is fixed in space, and you can’t tell exactly how many steps there are to climb. You heard from a friend that if you make it to the platform at the top of the ladder, you’ll receive an awesome prize. As you start to climb, the first few rungs are easy. You know that you can always climb down again if you decide it sucks. But for now, you decide to keep climbing.
Eventually, you climb up 100 rungs of the ladder, and you take a peek over your shoulder. You realize that the ground looks small and distant from this height. Also, the ladder has begun to wobble ever-so slightly. You’re not entirely sure that the ladder will remain structurally stable, but you’ve told yourself that whatever is up here, has to be good. Your friend wouldn’t lie to you, right? So you keep climbing. And climbing.
You’re now 300 rungs up--the ground is obscured by clouds. Birds are giving you side-eye. As you climb, some of the rungs below you break off and fall away. The ladder wobbles constantly now. You’re no longer confident you’ll be able to get down without help. But you’ve come this far... might as well keep going.
Now, if this were a physical ladder, I’m sure most of you would be like, “Nah man, I’d get down.” You’d tell yourself that you’re scared of heights, or that climbing an impossibly tall ladder just hanging there in space is suspect, or that peer pressure is beneath you. You’re elevated. You’re independent.
And yet, many of us (and I include myself in this bunch) are climbing an impossibly tall ladder, except that the ladder we’re climbing is not physical, but virtual. Still, just like a physical ladder, we take each rung one step at a time. We judge each step relative to the one preceding it. We never ask ourselves whether it makes any sense to keep climbing, or whether the goal is worth it, or who put this stupid ladder here in the first place. We’ve come all this way, after all, and maybe there really is something magical and life-changing at the top.
Keep the ladder image in your mind’s eye as you read. For today, gentle readers, I’m going to talk about the ladder OpenAI is building.
The first rung was, of course, ChatGPT in 2023. Then the Atlas browser, released in October 2025. ChatGPT Health, announced only a few weeks ago in January 2026, is yet another rung. But OpenAI and its CEO, Sam Altman, are still adding rungs for us to climb. Each will seem reasonable in isolation, relative to the steps we’ve taken before, because each new feature will seem genuinely helpful, interesting, or useful to us. But OpenAI isn’t building a system (only) to be helpful. It’s building a system to know us, completely.
As for the prize at the top?
It’s the complete picture of you.
I. Dr. Chat, GP
On January 7, 2026, OpenAI launched ChatGPT Health (or as I’ve been calling it, Dr. Chat, GP), a “dedicated experience” that allows users to upload their medical records (via data platform b.well), get advice, interpret lab results and health data, prepare for doctor’s visits, and integrate with fitness trackers and apps like Apple Watch and Peloton, as well as nutrition & shopping apps like Instacart.
According to their blog post announcing Dr. Chat, GP, users are desperately looking for health advice, with over 230 million people already posing sensitive health-related queries on ChatGPT. OpenAI claims that ChatGPT Health offers a better way to meet this need, with “purpose-built encryption”,1 strong privacy & security guarantees, and data isolation from other parts of the OpenAI ecosystem. But details on how this will be achieved remain elusive.
OpenAI’s Health Privacy Notice supplement (which distinguishes “Health content” from other forms of personal data), explicitly promises that Health content will not be used to train ChatGPT’s foundational models, or shared with vanilla ChatGPT.2 However, users can toggle the sharing of vanilla ChatGPT content with ChatGPT Health if they have Memories enabled.3
The Health Privacy Notice is silent on data sharing, retention, and other matters, so my default assumption is that these details are governed by language in the larger OpenAI Privacy Notice. In Section 3, the notice gives the company broad rights to share Personal Data with ‘trusted service providers’, affiliates, such as those under ‘common control’ with OpenAI, and to comply with government authorities, legal, or third-party requests. The legal requests language is broad enough to drive a tanker ship through. Here it is in full:
Government Authorities or Other Third Parties: We may share your Personal Data, including information about your interaction with our Services, with government authorities, industry peers, or other third parties in compliance with the law (i) if required to do so to comply with a legal obligation, or in the good faith belief that such action is necessary to comply with a legal obligation, (ii) to protect and defend our rights or property, (iii) if we determine, in our sole discretion, that there is a violation of our terms, policies, or the law; (iv) to detect or prevent fraud or other illegal activity; (v) to protect the safety, security, and integrity of our products, employees, users, or the public, or (vi) to protect against legal liability.
Note the sections highlighted in bold.4 For obvious reasons, Dr. Chat, GP will not be available in Europe, the UK, or Switzerland.
A few days after announcing Dr. Chat, GP, OpenAI acquired the four-person medical-records startup Torch for $100M, mostly in equity. Torch’s technology will purportedly help aggregate and unify scattered medical records, lab results, x-rays, and other structured and unstructured data into a centralized “medical brain.” Think Palantir, but for medical records.
OpenAI listed a number of pain points that ChatGPT Health can address. These include:
Centralizing diffuse medical information (hence the Torch acquisition).
Taking the burden off of short-staffed and overworked health providers by answering routine patient questions, explaining lab and test results using accessible language, interpreting data, and summarizing care instructions.
Dr. Chat, GP will also arguably do a better job keeping up-to-date with research & discoveries, which can be shared with care providers.
Healthcare costs are wildly unaffordable in many parts of the developing world and the United States. A cost-effective platform grounded in patient health data and validated by actual medical personnel might be the difference between a person seeking care or not. If Dr. Chat, GP can triage false alarms from actual serious events, people might be more inclined to seek treatment, rather than put things off.
230 million people already ask vanilla ChatGPT for medical advice.
Obviously, a safe, secure, medically-evaluated, legally-compliant system grounded in actual user data (and not WebMD posts) beats overworked and tired doctors, Dr. Google, or not receiving healthcare at all. And I fully support users being empowered to make better, more informed healthcare decisions. This product clearly fulfills a real need, and in isolation, Dr. Chat, GP has many upsides, and could potentially save many lives. But here’s the thing:
ChatGPT Health isn’t isolated. It’s also not really about your health at all. It’s one piece of a much larger puzzle OpenAI wants to solve: the entire picture of you.
So, today I want to talk about how I think OpenAI might go about attempting to solve this puzzle. How they will use this and future developments to piece together all the disparate pieces of data that make up each one of us. By the end of this piece, I hope to illustrate exactly what OpenAI’s end-game might be, and how they might go about getting there with our help.5
It’s worth clarifying that I’m not picking on OpenAI or Sam Altman here because they’re uniquely bad. I could probably write a similar piece on any of the big tech firms attempting to turn their foundation models into data everything-bagels. For example, a week after OpenAI launched ChatGPT Health, Anthropic announced its own version, Claude AI for Healthcare, which boasts similar features and integrations. Meanwhile, Google for Health has been plugging along for a decade, and I’m sure that we’ll hear about Gemini, MD or Dr. Grok shortly.
The reason OpenAI and Altman are getting the extra-special Carey treatment is because they’re the most nakedly transparent of the bunch. The trendline presented itself to me precisely because OpenAI brags about every single achievement, partnership, client, and investment in a way that most of the other companies are smart enough to stay quiet about. Also, Altman has absolutely no filter, and says the most cringe shit imaginable.
In the next few sections, I’m going to attempt to explain what I believe OpenAI’s next moves might be, based on reasonably sound evidence. I’m going to walk you through how high this ladder is likely to go, and explain how getting down again is going to be very hard indeed.
II. OpenAI needs us to keep climbing
Right now, OpenAI knows a little bit about a whole lot of people.
According to a recent Business Insider report, OpenAI boasts over 800 million6 weekly ChatGPT users (just shy of 10% of the world population), or if you want a flashier chart that looks more eyebrow raising, 3.2 billion monthly users.
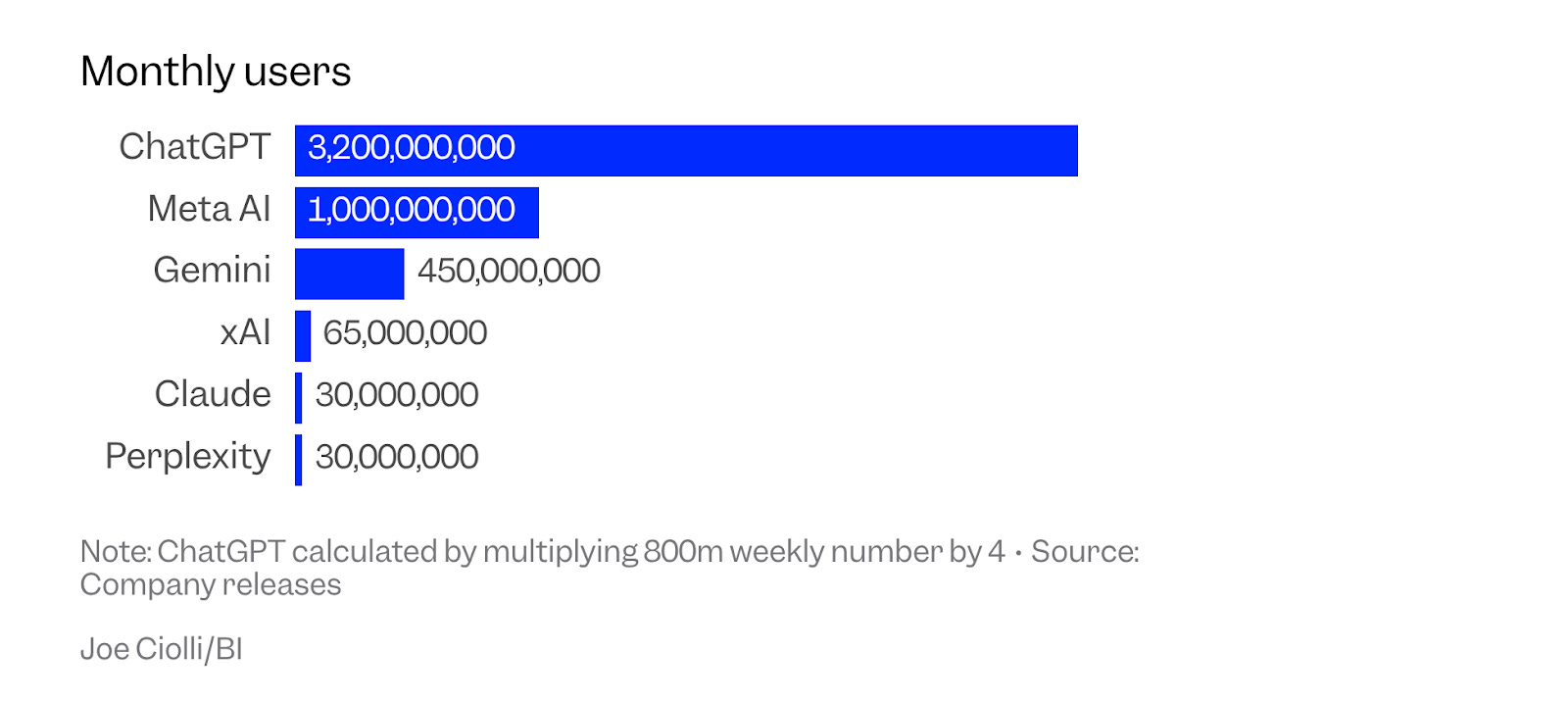
Source: Business Insider, “Sam Altman touts ChatGPT’s 800 million weekly users, double all its main competitors combined.”
ChatGPT has roughly 3x the users of Meta’s AI, 7x that of Google Gemini, 50x xAI, and over 100x the monthly users of Claude or Perplexity. That’s two orders of magnitude more users than the smallest competitors combined. OpenAI doesn’t just lead the market, it is the market.
But despite its enormous market saturation, the company is hemorrhaging money.
According to a January 18, 2026 blog post by OpenAI’s chief financial officer, Sarah Friar, revenue grew 10X from 2023-2025 ($2B to $20B+ ARR), which the company strongly correlates with compute capacity expansion (9.5X growth from 0.2 GW to ~1.9 GW). However, the company only projects total revenue of $145 billion by 2029, but expects to spend $115 billion to get there, indicating massive investment requirements. So, $145B - $115B is $30B, which ... isn’t exactly a big climb for a 3-year period. Maybe they’re just being conservative?
Beyond compute, OpenAI wants to diversify its revenue stream by expanding into other areas, including health and enterprise markets. The company recently announced that they would run ads on ChatGPT for free and low-tier paying customers to better monetize the 95 percent of ChatGPT users who don’t pay for the service. Friar also floated the idea of OpenAI entering into licensing deals, “IP-based agreements, and outcome-based pricing” (aka, revenue share) with clients who use ChatGPT for scientific research, drug discovery, energy systems, and financial modeling. “That is how the internet evolved. Intelligence will follow the same path,” Friar wrote in the January 2026 post.
I don’t know if these targets alone will make Altman (and more importantly, investors) happy. I suspect that if OpenAI eventually goes public, they’ll need to diversify further and consider alternative revenue generators beyond ChatGPT. To really make money, they need to build a bigger, deeper moat. Based on my research, I strongly believe that this moat entails building a massive, interconnected view about each user, something that even Google, Meta, or Amazon haven’t been able to achieve.
I believe this will involve prioritizing development efforts across a number of data collection points, all tightly integrated with one another. It might look something like this:
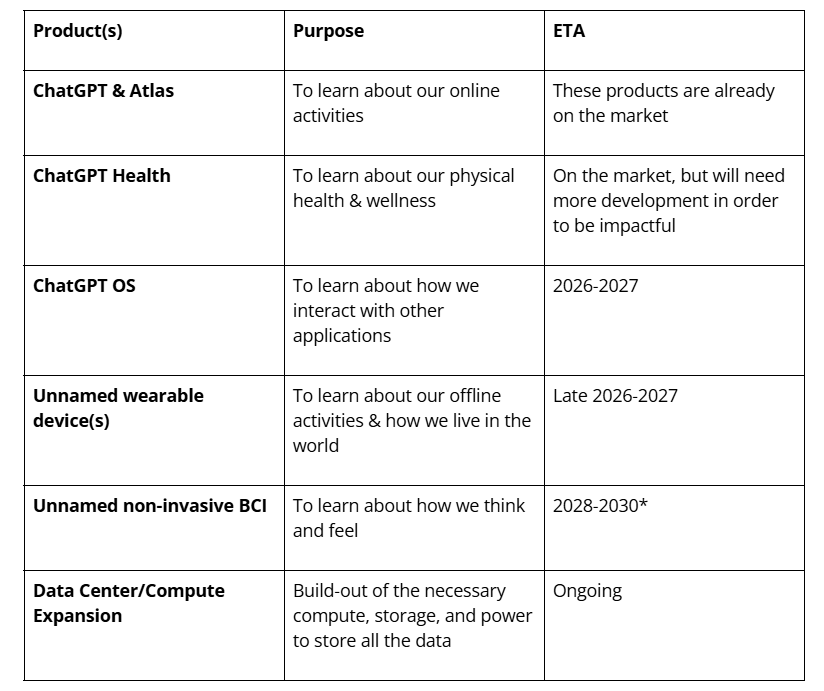
Each product will seem reasonable and useful in isolation. OpenAI will spend cycles touting the benefits and efficiencies of integrating each of these products within the ChatGPT-iverse, but won’t come out and explicitly say how that data is being combined and used. Instead, like every other big tech company, OpenAI will spread their intentions like tiny breadcrumbs, scattered across dozens of distinct privacy notices, help documents, and FAQs. The information will be there, but it will be up to us to put the pieces together.
In the end, if we’re not paying attention over the next 5, or maybe 10 years, these efforts will lead to the largest personal data grab that the world has ever seen. Exhaustive profiles of every user, true “digital twins” that can be created and sold to advertisers, governments, and used by the company itself, to profile us in a way that the laws currently do not anticipate.
Data protection laws, after all, focus on real flesh-and-blood humans, not digital avatars. After all, is it ‘profiling’ to endlessly A/B test a digital proxy of you? Is it ‘manipulation’ if the thing being manipulated isn’t even human? Advertisers do this already with focus groups and through careful trial-and-error, and this is generally fine, provided that the ad doesn’t obviously manipulate the person behind the screen. At what point does a perfectly crafted advertisement become subliminal and manipulative?
Unfortunately, given the current timelines, the pay-to-play griftonomics of the Trump era, and OpenAI’s ability to move quickly, I don’t anticipate meaningful regulatory resistance.
Before you accuse me of completely being off my nut and sharing that Always Sunny meme in the comments, hear me out. As I’ve said, Sam Altman is not great at hiding his intentions. He and OpenAI are openly telegraphing their moves. One just needs to piece through all the noise to see it.
I also want to premise that this assessment is highly speculative, and relies on making a few reasonable assumptions, any one of which could tank, or at least significantly hinder the dystopian end-game I’m presenting:
We must assume that OpenAI doesn’t run out of money, and Sam Altman continues to successfully convince VCs and other companies to throw exorbitant sums and resources towards these efforts. If the VCs get tired, stop believing the hype, no longer see how they’ll benefit, or the AI bubble otherwise collapses, I don’t think OpenAI will survive.7
AI scaling laws continue to hold --e.g., LLMs and other models will continue to improve provided that resources continue to grow. AKA: More compute/storage = more powerful models. Alternatively, model development efficiency gains occur in a way that bigness no longer matters.
Compute & chips continue to be accessible (at least for OpenAI). There’s a big asterisk here, given geopolitical dynamics between the US and China right now.8
Hardware and data center capacity are not meaningfully constrained through regulation/NIMBYism/power limitations, etc.
LLM providers vastly improve or eliminate long-running conversation limits.
World models, or something similar, become commercially viable. World models allow AI systems to understand real world constraints (physics, spatial properties, causality) and build internal models and simulations of the physical world to predict future states. I think this will be critical both in terms of how wearables operate, and for generating synthetic data, realistic digital twins, and efficient hypothesis testing.9
The “Jagged Frontier“ of AI systems’ abilities becomes less jagged.
Regulators and politicians continue to be slow to act, or are otherwise OBE when it comes to limiting OpenAI’s development efforts.
A major regime change does not occur in the United States before 2029-2030, which is the earliest timeline I can see OpenAI achieving this vision.
Things get more interesting and timelines increase if AI systems develop true artificial superintelligence (ASI) or artificial general intelligence (AGI). However, I am not basing my underlying analysis on whether ASI/AGI is achieved.
A. The Atlas browser and ads
A browser built with ChatGPT takes us closer to a true super-assistant that understands your world and helps you achieve your goals. OpenAI Blog
In October 2025, OpenAI released ChatGPT Atlas, the company’s AI-integrated browser. Built on Chromium, Atlas allows users to ask ChatGPT questions directly in the browser, summarize website content, do inline text editing, and, for premium users, autonomously perform certain agentic functions like booking hotels, shopping, and creating documents. The browser also remembers facts and insights from visited sites, and stores those memories on OpenAI servers. It then uses those memories to “learn” about user behavior & preferences over time and improve its usefulness.
Critics like Anil Dash have referred to Atlas and Perplexity’s Comet as “anti-web browsers“ because they replace web content with AI-generated summaries, while the Columbia Journalism Review pointed out that agentic systems are being used to bypass paywalls and content blocked by robots.txt files. Pew Research found that when AI summaries appear, users click on results only 8% of the time, compared to 15% without them — a 46% decline in click-through rates.
As I wrote in my November post, Agentic AI Browsers are Privacy Disasters:
Agentic-by-default browsers represent a big shift in terms of incentives and a huge downside risk for users with virtually no material upside. As someone more clever than me noted: with agentic AI, you’re the agent at the service of the AI companies. Or perhaps, more accurately, you’re the
moneydata mule for AI companies to engage in all sorts of questionable activities, largely liability-free.
If Atlas can provide users with results directly, users can bypass all the pesky ads, popups, and “experiential control“ mechanisms that sites use to upsell or monetize.10But don’t worry ... you’ll still get ads. It’s just that all that revenue will be piped directly into OpenAI’s coffers. But OpenAI pinky-swears that they won’t sell user data or expose conversations to advertisers, and that they won’t advertise to under-18s, or on “sensitive topics” like health or politics. Oh, and they promise that answers won’t be influenced by prompts.
Folks, if you believe that, I’ve got a ladder I want you to keep climbing.
Having ads in ChatGPT was inevitable, but it’s fun to look back on how Sam Altman has shifted his position on the ads question, as money became a more pressing concern:
“Ads plus AI is sort of uniquely unsettling to me,” Altman said during an event at Harvard University in May 2024. “I kind of think of ads as a last resort for us for a business model.” (source: Business Insider)
B. ChatGPT OS
“Gross oversimplification, but like older people use ChatGPT as a Google replacement. Maybe people in their 20s and 30s use it as like a life advisor, and then, like people in college use it as an operating system.” Sam Altman, at Sequoia Capital’s AI Ascent Conference
OpenAI is very interested in expanding ChatGPT beyond a single app into a whole operating system.11 Though they aren’t really calling it an OS, so much as a “developer ecosystem” within ChatGPT, which is expected to launch sometime in 2026, according to Wired.
ChatGPT OS will include agentic features and outcome-based agentic actions. For example, users might ask an AI agent to buy theatre tickets or book a hotel using an “instant checkout” feature. At OpenAI’s demo day conference, in October 2025, Sam Altman boasted about how application developers like Canva, Zillow, and Spotify are already building integrations directly into ChatGPT (thus avoiding the need for users to run separate applications or visit websites).
Still, software developers might want to think a bit before giving into short-term partnerships with OpenAI – ChatGPT OS could have profound impacts by disintermediating “companies from their users,” particularly for applications that rely on users for upsells or advertisements.
I also suspect that any ChatGPT OS will include some form of Microsoft Recall-like memory, taking continuous snapshots of user interactions and behavior that can be accessed by ChatGPT. I’ve explored why AI-integrated operating systems like Recall are a terrible idea quite a few times here, here and here. Always-on, always-logging systems are terrible for users for a dozen different reasons. Still, I can’t imagine a world where OpenAI doesn’t go there.
C. Sam Altman really wants Her
“You trust it over time, and it does have just this incredible contextual awareness of your whole life.” Sam Altman, at Emerson Collective’s 9th annual Demo Day in San Francisco
No, I’m not referring to Sam’s love-life. I’m talking about Samantha, the advanced AI operating system in Spike Jonze’s 2013 dystopian sci-fi film Her, which foretold a future where techno-human relationships were not only possible, but socially accepted. Altman has a well-documented fascination with the movie. For example, when ChatGPT 4o’s voice feature was released in May 2024, the voice demo bore an uncanny resemblance to Scarlett Johansson, who voiced Samantha in the movie. In fact, the voice was so on-point that Johansson threatened legal action, and Altman went into damage control and changed the voice.
Also, it didn’t help matters that OpenAI had previously asked Johansson to lend her voice in 2023 (she declined) AND posted this cryptic tweet on launch day:

In May 2025, OpenAI acqui-hired Apple’s visionary designer, Jony Ive in a $6.5 billion acquisition of Ive’s startup, io. In January 2026 at Davos, OpenAI’s chief global affairs officer confirmed that the company has been working with Ive on a screenless, likely wearable “secret device“ with an expected launch in late 2026.
On January 12, 2026, X user ‘Smart Pikachu’ leaked Project “Sweetpea“, which may be the device in question. It’s earbud-like, though quite different from traditional earbuds, consisting of two capsule-shaped components (perhaps magnetically linked), a custom 2-nanometer processor and some means to handle AI tasks locally instead of sending requests to the cloud.12 The device will consist of two chips, one of which would enable iPhone control through Siri. Material costs are reportedly close to smartphone level, according to The Decoder.
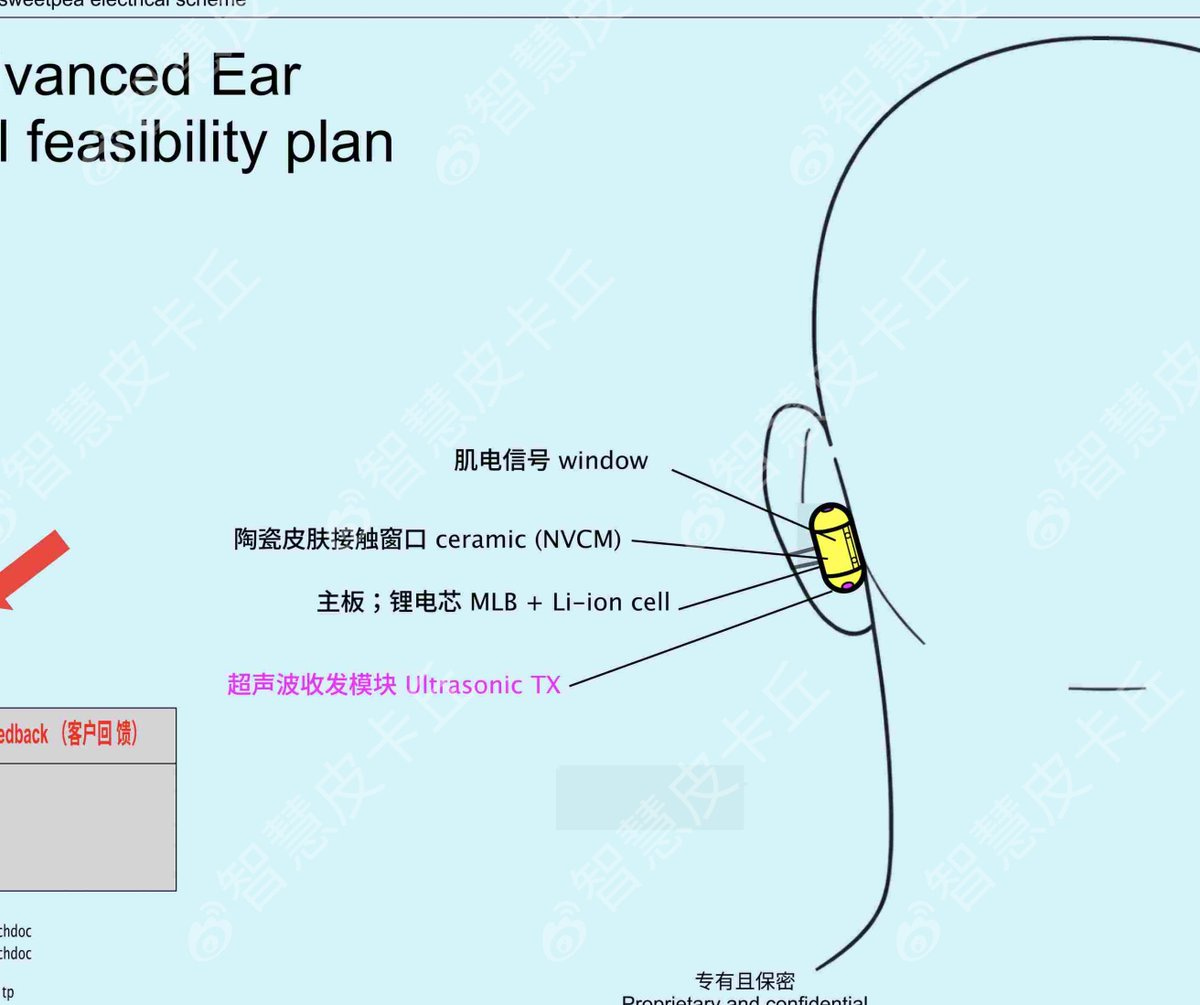
Source: Smart Pikachu (The Nazi Bar)
According to the leak, Sweetpea may launch as early as September 2026, which lines up with a ‘late 2026’ launch. The leak also mentioned that the company plans to build 40 to 50 million units within the first year.
Other reports suggest that OpenAI is also working on a palm-sized screenless device. According to TechCrunch, the goal is to have a device (wearable or otherwise) that is fully aware of its user’s surroundings, small enough to fit into a pocket, that can be fully integrated into daily life.
And like clockwork, Apple announced that it is also working on a wearable, with an estimated delivery date of 2027. Like I said above, nothing is particularly unique to OpenAI here. The ladder would still be the same for any of these AI ecosystems.
D. Sam Altman really wants your brain
“Brain computer interfaces (BCIs) are an important new frontier. They open new ways to communicate, learn, and interact with technology. BCIs will create a natural, human-centered way for anyone to seamlessly interact with AI.” OpenAI announcement about Merge Labs investment (January 15, 2026)
“I think neural interfaces are cool ideas to explore. I would like to be able to think something and have ChatGPT respond to it.” Sam Altman’s August 2025 dinner date with The Verge’s Alex Heath
Finally, I’ll touch on one speculative development that Altman is involved in: a new brain-computer interface (BCI) startup called Merge Labs. On January 15, 2026, Merge Labs, co-founded by Alex Blania13 and Sandro Herbig raised $252 million in seed funding, led by OpenAI, Bain Capital, Gabe Newell (co-founder of game developer Valve)14 and others. In true Techbros-Ignoring-Cautionary-Tales fashion, the company’s name refers to the singularity, or “merge” point, where human brains and machine intelligence combine, with or without genetic enhancement, because of course. Sam even wrote about the merge in 2017.
Unlike competitors, such as Neuralink, Merge Labs—which was spun out from the nonprofit research org Forest Neurotech—plans to use non-invasive ultrasound technology and molecular interfaces rather than invasive brain implants to do that merging. And this isn’t completely speculative: Forest Neurotech already developed a research-grade ultrasound scanner (Forest 1), which is “smaller than a standard key fob” and detects brain activity through blood flow changes rather than direct electrical neural measurement like an EEG.
This allows for “functional brain imaging and neuromodulation from surface to deep brain structures in humans,” according to the Forest 1 product page. What differentiates the technology from other non-invasive competitors is the small form factor, and capacity to interface with the entire brain at high-bandwidth.
Still, there are quite a few steps between ‘small device that can read brainwaves quickly’ and ‘small device that can be used to read brainwaves quickly that is also interpretable by ChatGPT.’ To get to that point, OpenAI plans to collaborate directly by providing foundation models, frontier tools, and likely engineering support, using AI as both a development accelerator and an OS.
Oh and there’s also this:
Merge Labs is exploring a unique technological approach that combines gene therapy with ultrasound-based neural monitoring. The proposed system would genetically modify brain cells to make them more compatible with implant technology, according to people familiar with the plans who weren’t authorized to speak publicly. An ultrasound device implanted in the head would then detect and modulate activity in these modified cells.
This approach differs significantly from existing brain-computer interface technologies, including those developed by Neuralink and other companies, which primarily rely on electrical signals to communicate with the brain rather than ultrasound-based systems.
Now, billionaires fund crazy galaxy-brain shit all the time, and this could all end up going nowhere. There are a lot of steps between funding a non-invasive ultrasound BCI device and getting people to actually use and pay for it. However, Merge Labs is not the only company interested in developing non-invasive BCI, or even non-invasive ultrasound-based BCI. For example, Bryan Johnson (the billionaire founder of Braintree, who now spends his time trying to live forever by injecting his son’s blood) founded Kernel, which is also developing a consumer-grade ultrasound BCI device that looks an awful lot like a scooter helmet. There are also a dozen other companies developing consumer-grade non-invasive BCI devices.
Even though I give this misadventure around 25-30% odds of success, But my opinion doesn’t really matter. What does is that Altman and a bunch of other people with more money than I’ll ever have in my life think it’s possible. A $250M funding round can still get a lot of research done; it can buy a decent amount of compute, engineering resources, and more importantly, hype & VC FOMO.
E. OpenAI needs infrastructure
This post has grown insanely long, so I decided for reasons to include a brief meme break. I hope you enjoy15
Beyond product, a priority for OpenAI (and all the other frontier AI companies) is around infrastructure. Namely, how to manage the positively unfathomable amounts of data they’ll need to grow their business, and how to get the AI systems to handle increasingly complex tasks, maintain longer and larger context windows, and have longer recall.
OpenAI is already in talks to purchase billions of dollars worth of data storage, hardware (particularly chips), and software capacity, and has been shopping around for upwards of 5 exabytes of data storage, which is equivalent to 5,000 petabytes, or five billion gigabytes.16 The company has already committed roughly $1.4 trillion on data center projects over the next eight years and is, according to CEO Sam Altman, five years away from profitability.17
In January 2025, shit got real when OpenAI announced the Stargate AI infrastructure joint venture. The JV will include Oracle, MGX, OpenAI, and SoftBank as funders,18 while Arm, NVIDIA, Oracle, and Microsoft will be the initial technology partners. Naturally, the internet greeted the news with the kind of sober, respectful response that one has come to expect with such an announcement:
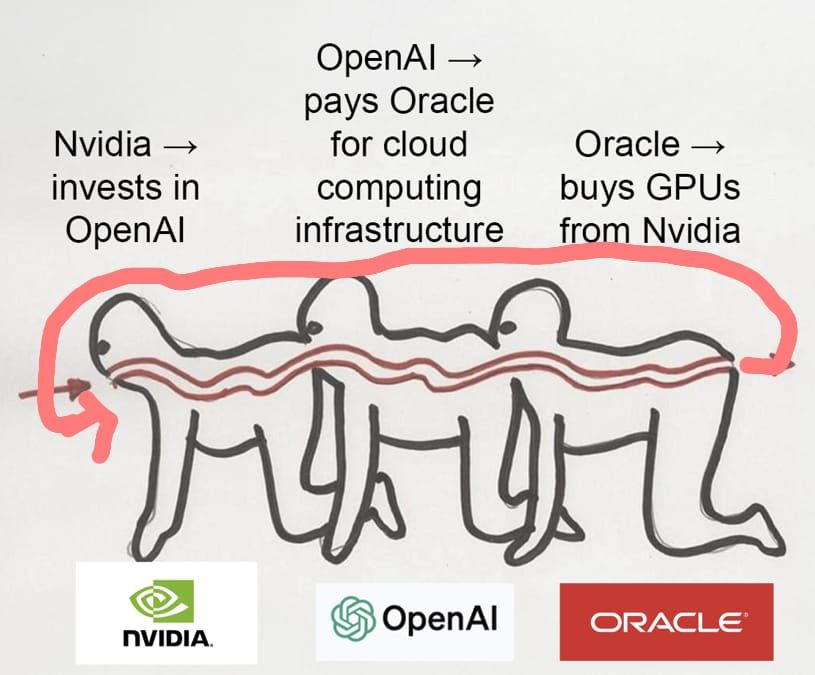
OpenAI is also throwing small country-GDP-levels of cash at the compute problem, based on the assumption that More Compute = Better Models = Moar Money. This is sadly not a meme:
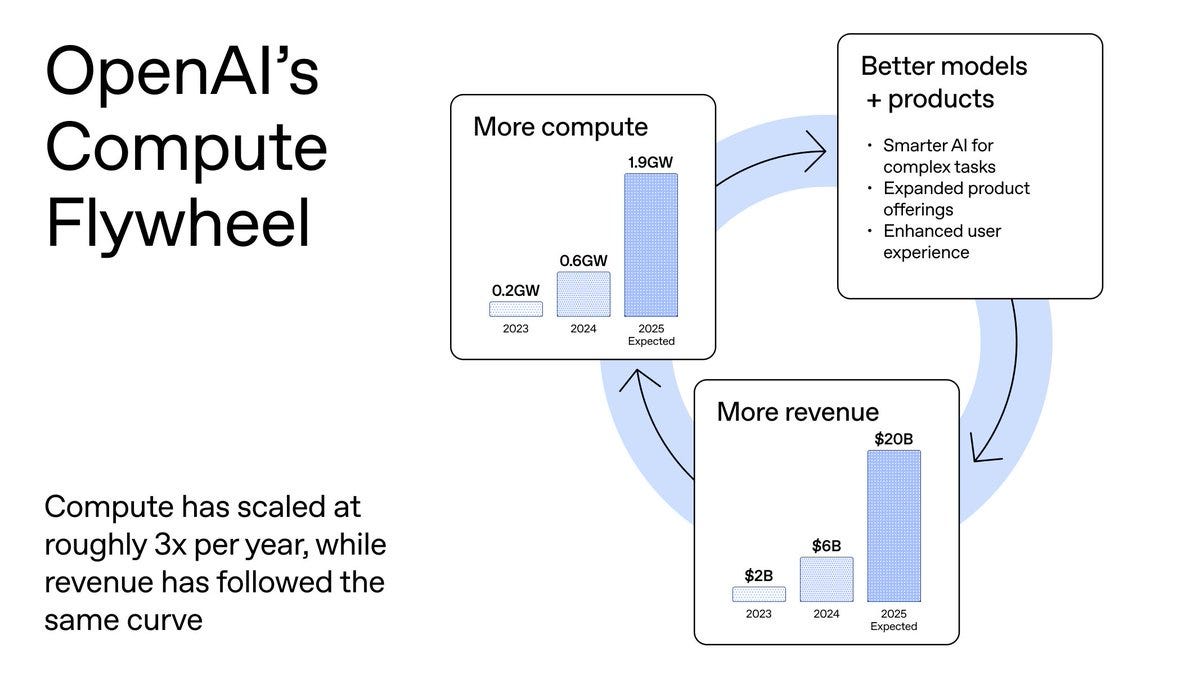
In addition to Stargate, OpenAI has also entered into a number of smaller strategic partnerships with chip and compute providers. These include:
NVIDIA ($100B+): In September 2025, OpenAI partnered with NVIDIA, agreeing to build at least 10 gigawatts (the equivalent to 10 nuclear power plants) of AI data centers using NVIDIA systems and GPUs, in exchange for a $100 billion in investment by NVIDIA.
AMD: In October 2025, OpenAI also began courting another GPU girlie, when it entered into a strategic partnership with AMD, where the company agreed to deploy 6 gigawatts of AMD GPUs based on a multi-year, multi-generational agreement, starting in the second half of 2026.19 AMD also issued OpenAI 160 million shares of AMD common stock, designed to vest as specific milestones are reached.
Amazon Web Services ($38B+): In November 2025, the company signed a 7-year, $38 billion deal to use AWS for training and inference, with capacity coming online through 2026.

Cerebras Systems ($10B+): In January 2026, OpenAI signed a deal for 750MW of low-latency compute, utilizing Cerebras’s specialized, single-chip systems for faster inference. There appear to be no memes here, probably because few people have even heard of Cerebras Systems.
Finally, this also isn’t a meme, but it’s a good visual of how circular these arrangements are. As I said earlier, the biggest assumption that will tank OpenAI’s vision as I see it, is if this flywheel breaks.
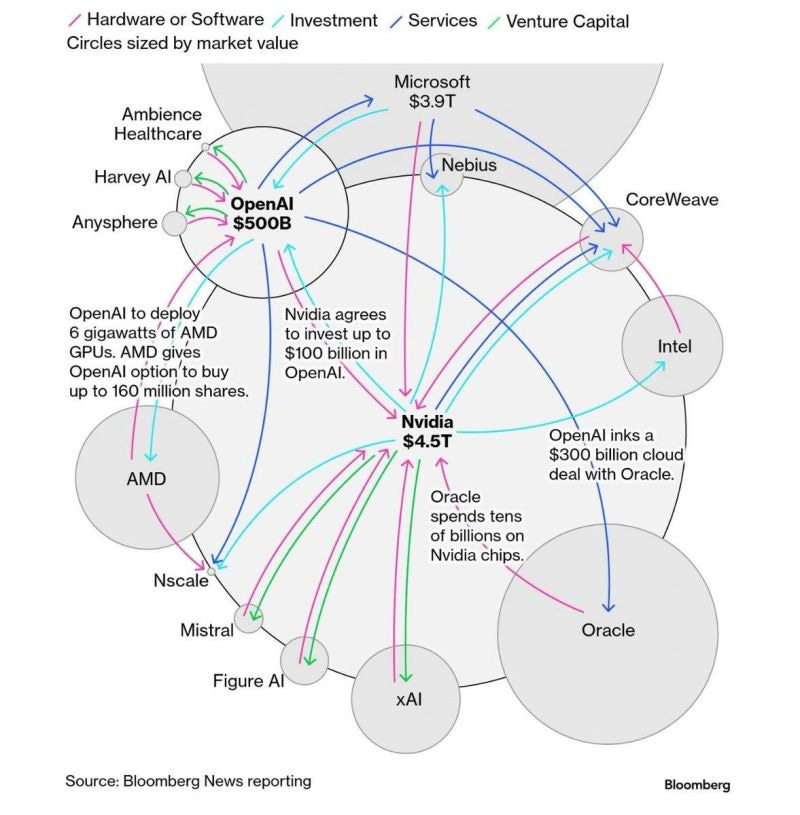
Right, so I think I’ve laid the groundwork for my larger thesis, which I’ll explore in the next post.
Here’s the Tl;Dr for you short-attention span folks:
OpenAI is hemorrhaging money at an unsustainable pace, it spends 3x what it earns, and only 5% of its 900M users pay.
Regular context-based ads and a 5% paid subscriber base will not solve this problem.
OpenAI needs something that will bring them real revenue, not just scraps. They know that the VC gravy-train won’t last forever. To get there, they need to start developing new devices, and finding ways to capitalize on new revenue streams.
And so, they’re going all in on building their products, ecosystem, and infrastructure now hoping that in 5-10 years, things will pay off bigly.
In the next section, I’ll dig into what that means in practice, and a plausible scenario of why many of us will keep climbing the ladder they’ve set out for us.
Until then, sit with this and think about what a world like this might look like. Ask yourself, how far up this ladder are you willing to climb?
And please tell me I’m not screaming into the void.
Part 2 is now available:

I hope for the sake of everyone, that this is not 'roll-your-own' encryption, because that would be a nightmare.
Defining personal information, much less sensitive personal information like health information and records as ‘Content’, makes me die a little inside, but such is the world we live in.
See Section 4 of the Health privacy notice.
For example, will health information be supplied to Ken Paxton in Texas if he issues a court order looking for pregnant women who may have had a miscarriage? If he asks nicely? Will the DOJ be able to compel OpenAI to turn over records of kids and teenagers who are transitioning based on a Donald Trump tweet? What about immigrants? Will OpenAI use your health information against you in a wrongful death case, or if a third party insurer sues OpenAI? Who knows?!
Since I use Claude as an editor, and have told it to be brutal, it reminded me that I use a lot of hedging language in my writing. It’s not wrong, but in this case, hedging is necessary. I don’t have a crystal ball, nor do I have insider information. What I do have is a fair bit of research supporting these conclusions and a well-developed pattern-matching skill.
In December, The Information (which is paywalled) claimed that OpenAI has actually reached 900 million weekly users, but they didn’t create a cool bar chart like Business Insider, so I’m going to go with the slightly lower numbers.
However, as I mentioned above, this approach could be replicated. Maybe it's not OpenAI, but Google or Anthropic, or god forbid, Facebook or xAI.
Trump is an idiot, and his asinine policies may end up setting the US back for decades, which may further weaken access to the rare earth minerals and chip development necessary to continue this expansion. If China continues to grow, and the US continues to deport some of the best and brightest, all bets are off.
There’s a good breakdown of why world models are the next big thing here: https://www.nextbigfuture.com/2026/01/agi-needs-world-models-and-state-of-world-models.html
I was at a recent OpenAI hackathon event in Dublin. While enjoying a few pints, I got to chatting with one of the engineers who is involved in a related privacy-focused project. They mentioned how this could be applied to counter privacy-abusing websites (for example, those who do not honor Global Privacy Control signals. I don't want to share too much, as it hasn't been released, but even I was impressed with this particular use of what otherwise seems like the height of gatekeeping.
As are Amazon and Meta, for what it's worth.
Who wants to take bets on whether the earbuds will have an AI voice that sounds uncannily like Johansson again.
Fun fact: Alex Blania is a co-founder of Merge Labs. If that name rings a bell, it's because Blania and Altman also founded the eyeball scanning company Worldcoin (now World), which has faced lots, and lots, and lots of controversy.
Bonus fun fact: This is not Newell’s only adventure into BCIs -- in 2019, he founded BCI startup Starfish Neuroscience, which is developing a “minimally invasive” implantable chip.
I cannot begin to tell you how much joy I experienced finding these memes. Every time I look at them I giggle, and I am reminded that humans will still probably reign supreme in pwnage, even after the merge happens or we achieve AGI or whatever.
To put this in perspective, let’s compare OpenAI with Google for a minute. A July 2024 research report by ABI Research estimated that Google has around 130 operational hyperscale data centers. In a March 2025 Google Cloud blog post, Google Cloud engineers shared that each data center has one Colossus filesystem per cluster per data center, and that a few of these clusters store ten exabytes of data or more. Doing some very simple back-of-the-napkin math (i.e., the Google calculator), if Google has 130 data centers, each with only a single cluster, and those clusters store just 1 exabyte of data each, that’s 130-150 exabytes total (if you factor in the two that definitely have 10 exabytes). Five exabytes really isn’t that much.
Still, I don't think OpenAI will stick with 5 exabytes, given the company's grand visions. To do what I’m speculating, we're talking zettabyte- or even yottabyte levels of data storage. For context, a zettabyte is 1 million petabytes, or 1 trillion gigabytes of data, approximately all the data generated worldwide in 2016, while a yottabyte is 1,000 zettabytes, and no one has reached this point yet.
You might be asking yourself why is Carey harping on storage so much? Well, a fancy cognitive neuroscientist at Northwestern University named Paul Reber, estimated that the human brain has a theoretical storage capacity of 2.5 petabytes, or 2.5 million gigabytes. Let's say, OpenAI manages to secure 1 billion users, and 20% of them, or 200,000,000 are willing to pay for the full BrainGPT experience I've laid out above. If we get to the point of creating a full digital version of each individual's brain, that's 500 zettabytes of storage. Double those numbers, and we're in yottabyte territory. Maybe they can squeeze by with just exabytes through compression or some other fancy digital jiggery-pokery, but it’s still gonna be way more than a few exabytes we’re talking about.
Coincidentally, Oracle and MGX are also partners in the new American TikTok acquisition, and importantly, they have the full backing of the current administration. This further supports my cynical position about why I don't believe regulators will save most of us. The EU, perhaps excepted, at least until they capitulate again.
Just in case you were confused like me, this refers to chip generations, not grandchildren.
Putting all of this together and managing not to sound like a conspiracist! Love this digging and the ladder metaphor, thank you
This is an incredible deep dive into OpenAI's plans for the future! I knew that ChatGPT alone could never generate enough revenue to support the company's current operating costs and future ambitions (even with enterprise revenue), but I didn't realize how expansive their efforts already are.
While I'm sure they can extract an immense amount of value from our data, I suspect the time horizon for that will be quite long. I'm not sure how long their investors can keep footing the bill, because even reaching break-even seems like a long road, and profitability seems further still.
Can't wait to read the rest!