Can LLMs Unlearn? Part 2: Needle in a Neural Network - In Order to Forget You, First You Must Be Found
This is Part 2 in an N-part series where I try to figure out if data subject rights (and other data protection obligations) are achievable with LLMs. In Part 2, I discuss the identification problem.
For those of you who are following along, this has been a many months-long quest to discover whether or not large language model (LLM) providers can comply with data subject rights like the right to erasure & the right to be forgotten (RTBF) and whether LLMs generally can unlearn. To make life simpler for everyone, I’ve created some breadcrumbs.
In Part 1, I lay out the problem: LLMs are not databases, and yet our laws expect them to behave like databases. Data protection laws in particular, assume that the things that hold true for databases should be as easy to do for a non-deterministic systems like LLMs. I begin to explain why this is hard.
In Part 2, I start to dig into one reason this is so hard —what I call the ‘underpants gnomes/Which Napoleon’ problem. I ask the key question of how to identify a specific individual within a system in order to erase or correct information about that individual. I also touch on how applying certain tools during the initial training process can help, such as Named Entity Resolution, Named Entity Disambiguation, Linking & Knowledge Graphs, but how that’s also really costly which is probably why no one is doing it.And Part 2 here:
Part 2.5 discusses my ongoing efforts to have OpenAI (and less successfully, Perplexity) forget my data. OpenAI kinda tries, but it never actually erases data about me. It just applies a rather blunt-force hack to the problem. I discuss whether this is sufficient and potential harms from this approach:
In Part 3, I start to explore the research on machine training and unlearning. I define what machine unlearning / forgetting is, and isn’t, and address the techniques researchers have discovered. I also explain why the gold-standard approach of starting with perfect data or full retraining doesn’t scale well, and why other exact unlearning methods are also difficult to do in practice:
Part 4 continues the technical discussion. In this section I touch on approximate unlearning methods, their strengths and limitations. I also discuss adjacent unlearning techniques like differentially private unlearning and federated unlearning:
In Part 5, I will cover the final bits, including suppression methods & guardrails — essentially what OpenAI does to ‘comply’ with data protection laws like the GDPR. I will also close with my thoughts on the state of the law, and how to reconcile the incongruence between technical complexity and legal certainty.
You are here: Part 2 … Understanding what to unlearn — the Underpants Gnome/Which Napoleon? problem.
If you’re reading through this entire saga, you clearly like my work. Perhaps you like it enough to subscribe?
How does OpenAI/Perplexity/Google/Anthropic ‘find’ the data in the first place?
Houston, We Have Some Problems
Let’s say I send a deletion request in relation to my personal data to OpenAI and Perplexity (which I actually did, because I’m me). Specifically, I want this query and output to go away, and more importantly, any future content or associations about Carey Lening the data protection consultantor Carey Lening in Dublin, Ireland, or Carey Lening who really likes cats to return a variation of “I’m sorry, Dave, I don’t know who Carey Lening is”.
What I do not want is for OpenAI to just delete my account information and be done with it, because that’s boring.1 I also don’t necessarily want OpenAI to delete information on other Carey Lenings that exist in the world.
In a normal erasure/RTBF context, this is a relatively straightforward process.
I file an erasure/RTBF request. In the case of a RTBF request, I include the link(s) I want to be forgotten.
If the controller (e.g., OpenAI) has questions about my identity, or which Carey Lening record/object to delete, they might ask me for some additional details (like account information, the email I signed up with, some form of identity document, etc.).
OpenAI will then comb through their databases and purge (or otherwise anonymize) data associated with me, and only me, unless they can avoid doing so by relying on an exception. For a RTBF request, they’ll suppress the links they have about me, absent an exception.2
But with LLMs, there’s no ‘record’ stored as such. Remember, words are broken up into tokens (or vector embeddings).3 As I noted in Part I of this saga, LLMs do not store data in the traditional ‘filing system’ sense of the word:
Large language models use training data (like the Common Crawl) to learn what words are most likely to appear next to other words. It then assigns words (or parts of words, word stems, or other characters) to a token. For example, here’s how OpenAI breaks down the phrase “Carey Lening is a data protection consultant based in Dublin, Ireland:
You can play around with OpenAI’s token generator here.
You might notice that tokens don’t always translate to words. Carey for example, is a combo of ‘Care’ and ‘y’ which makes some sense – ‘Care’ is a common word, and it’s less common to append something like -y, -s, or -t) to that. More common names like Bob or David don’t do that stemming thing because they’re already common.
While there’s some dispute in the research and legal communities about whether training data is memorized or not,4 the general consensus is that an LLM is a huge black box, and storage or retrieval of a specific record or document from the training data is realistically not possible, at least without some clever prompt hacking. And even if it was easy to do, it’s kind of like trying to find a very specific grain of sand at the world’s biggest beach.
Many computer & data scientists and math nerds find the erasure/RTBF problem to be very interesting. There’s loads of information out there on different methods to suppress or put guardrails around data, on the best methods for retraining models, or exotic methods of getting machines to unlearn. There’s tons of sexy discussion about altering gradient descents, and ablating stuff, or catastrophic forgetting. And there’s math. My god, there’s so much math.5
The trouble is, the researchers are mostly interested in the erasure/RTBF problem as a vehicle to explore the math bits. And because those researchers are primarily working with small datasets focused on a discrete problem (like getting a model to forget the number 9, or Napoleon Bonaparte, or a specific cat picture), they ignore a very important problem: how do we identify the right data to delete or forget?
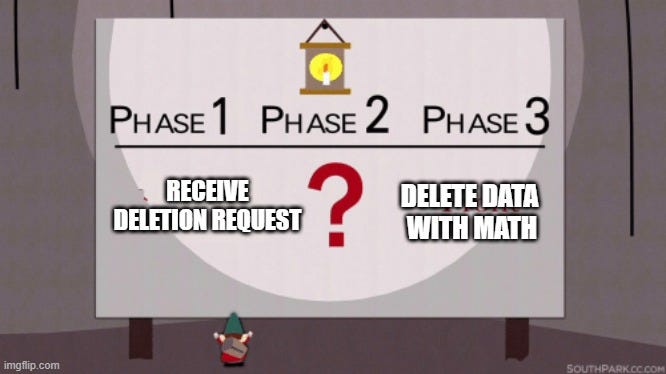
To formalize things, I’ve broken this problem into three distinct steps/phases:
Step 1: Receive a deletion/RTBF request from a user.
Step 2: Find all the data you want to delete/suppress/unlearn/forget.
Step 3: Use lots of fun exciting math and algorithms to get the LLM to delete/suppress/unlearn/forget the data.
Now, I don’t have a precise answer as to why Step 2 is generally ignored or, more likely, why I haven’t been able to find much research on it. Maybe it’s considered a solved problem (it’s certainly easy with tiny datasets). Maybe they’re not thinking big picture. Maybe they don’t care? Either way, we’ve got an underpants gnomes problem on our hands:
We have an underwear gnomes problem.
Some Prior Assumptions
Before I jump into the Step 2 problem, I wanted to lay out a few assumptions I’m making here:
For the purpose of my analysis, I’m focused primarily on LLMs —ChatGPT 4o, Claude Sonnet, Gemini Ultra, and Meta’s LLaMA models. I say primarily LLMs, but I think many of these questions can apply to other Deep Neural Networks (DNNs), as LLMs are a subset of DNNs.
A diagram showing the nested nature of where LLMs fit in the hierarchy of “AI”. This was created by Claude because I suck at drawing and art of any kind.
In AI Act parlance, I’m looking at this from the lens of ‘general-purpose AI models’ more than ‘AI systems’.6 If I’m also including AI systems in my analysis, I’ll try to be clear about that.
In the law, there’s a distinction between erasure/deletion and the right to be forgotten (RTBF). But, for purposes of this part of the analysis, let’s assume that either RTBF or erasure can be requested by a data subject.7
I am taking the position that LLMs do not store data in the traditional Article 4(6) GDPR ‘filing system’ sense of the word, which is to say ‘a structured set of personal data which are accessible according to specific criteria’.
However, I am assuming that GPAI providers and deployers of GPAI in AI Systems which process personal data, must fully comply with the data protection laws, including data subject rights.8 So far, only the Hamburg DPA has taken a more nuanced view on this, and based on my read, only in relation to LLMs (GPAI? AI Models?). I will discuss the Hamburg thesis towards the end.
Now, we get into the fun — how do we approach the Step 2 problem?
Entity Disambiguation, Knowledge Graphs, and Named Entity Resolution
I do love the LinkedIn community because my crazy questions usually do get thoughtful answers.
Technically, Step 2 consists of a few distinct processes. Named Entity Resolution, Named Entity Disambiguation, Entity Linking, and the use of Knowledge Bases & Knowledge Graphs.
Named Entity Recognition/Resolution (NER) or Named Entity Extraction (NEE): NER/NEE is the process of identifying and classifying named entities found in unstructured text into semantic categories. When I talk about named entities, think categories of things — a person, an organization, a location, an event, a date. In the context of LLMs, NER/NEE is usually applied at the training stage, and is crucial for identifying an individual from say, an event or location.10 Say for example, you’re working with the following text:
Napoleon Bonaparte, born 15 August 1769 – 5 May 1821, later known by his regnal name Napoleon I, was a French military and political leader who rose to prominence during the French Revolution and Napoleonic Wars … he is the father of Napoleon II, and the paternal uncle of Louis Napoleon Bonaparte (Napoleon III).
A NER pipeline/tool might assign entity classifications to each type of entity. For example: PER = person, DAT = date, EVN = Event, MISC = something else, along with a score of the tool’s rough confidence in its entity classification. To better illustrate this, I used one of the many NER classifier tools out there (specifically the NER-powered Search Collab Notebook), which are fun to play with, but take a bit of technical skill to understand.11 Here’s how the NER Search Collab tool processed the text above:
[{'entity_group': 'PER',
'score': 0.99584633,
'word': 'Napoleon Bonaparte',
'start': 0,
'end': 18},
{'entity_group': 'PER',
'score': 0.88984483,
'word': 'Napoleon I',
'start': 85,
'end': 95},
{'entity_group': 'MISC',
'score': 0.9996966,
'word': 'French',
'start': 103,
'end': 109},
{'entity_group': 'EVN',
'score': 0.9941884,
'word': 'French Revolution',
'start': 174,
'end': 191},
{'entity_group': 'EVN',
'score': 0.99439585,
'word': 'Napoleonic Wars',
'start': 196,
'end': 211},
{'entity_group': 'PER',
'score': 0.7871858,
'word': 'Napoleon II',
'start': 234,
'end': 245},
{'entity_group': 'PER',
'score': 0.9812725,
'word': 'Louis Napoleon Bonaparte',
'start': 293,
'end': 317},
{'entity_group': 'PER',
'score': 0.7002603,
'word': 'Napoleon III',
'start': 319,
'end': 331}]
You might notice that the NER step doesn’t necessarily catch or properly classify every entity. For example, the NER tool I used missed dates, titles, and France as a location. There are many tools that are designed to do this in a somewhat automated way, including OpenNLP, GATE, NLTK, Stanford CoreNLP and all apply different methods of NER, with different types of classification and levels of precision.12
What’s important to understand is that these tools aren’t perfect, and more importantly, NER only categorizes entities, but it can’t distinguish between them.13 For that, you need disambiguation.
Named Entity Disambiguation (NED) and Entity Linking: Once entities are categorized, they must be distinguished from one another. Even if we know that Napoleon can be a person, it may also refer to a location (Napoleon, Arkansas), a fictional character, or the 1951 film Napoleon. This process is known as disambiguation, or Named Entity Disambiguation if you’re being fancy. Wikipedia provides a really good example of what disambiguation might look like:14
Current methods for NED involve measuring the similarity between a named entity in some corpus of unstructured text against a pre-populated knowledge base of information like Wikidata, DBpedia, or a more domain-specific knowledge base. Context is really important here: If the context of Napoleon in the reference text is a discussion about the pig in Animal Farm, disambiguation helps the model associate the correct Napoleon in the knowledge base (i.e., the pig, not the French leader).
The closer the context is between the reference text and the knowledge base candidate entity (or entities), the higher the confidence score, and the more likely the disambiguation process is to assigning a proper match.
Once there’s a match, the next step is to link the unstructured but newly-identified entity to its knowledge base entry. This is known as entity linking.
There’s actually a really cool (albeit slightly unintuitive) visualizer for testing disambiguation to linked entities, created by the Max Planck Institute for Informatics using the AIDA framework. I will not even begin to get into explaining how the specific dials and knobs work, but in short, it provides some example text (“Napoleon was the emperor of the First French Empire…”) and depending on how you fiddle with the sliders & knobs, you get more or less accurate candidate entities, which is to say a specific Napoleon vs. many Napoleons. You also get varying degrees of confidence regarding which Napoleon the reference text might be referring to.15
What I love about this example is that you can quickly see how hard it is to disambiguate the correct Napoleon on a specific isolated piece of text tied to a single source (Wikipedia). While you can get it to return a single Napoleon (by selecting a low ambiguity and a defined entity type), you also get a number of probable Napoleons, depending on which record you chose.
Knowledge Bases & Knowledge Graphs: Another critical component of this whole process concerns knowledge bases and knowledge graphs. These are similar, but slightly different things. A knowledge base is (usually) a static table with rows and columns, usually in a database or or other structured format. A knowledge base contains details or characteristics about an entity (like name, date of birth, location, genus/species, whatever).
Knowledge graphs, by comparison, are organized, dynamic collections of data rendered in a graph structure. This graphical nature allows for characteristics about the entity itself (referred to as a node) to be shared, but also the semantic relationship between the specific entity node to other nodes. This relationship or link is referred to as an edge.
A knowledge graph about Napoleon might include person nodes for Napoleon Bonaparte and Napoleon II, a date node like 15 August 1769, and an event node listed as the ‘French Revolution’, with the respective relationship edges between them (father of, born on, involved in). I have way more about knowledge graphs and a related concept called social network graphs here.
As with NER, a confidence score of the entity linking might be applied to the whole mess based on the context clues provided in the reference text. The confidence score is what an LLM or GPAI model would use to decide on the correct result for a specific query (‘Who is Napoleon Bonaparte?’).
There are many tools to automate the generation of knowledge graphs & knowledge bases, and then conducting NER and NED processes. Some researchers even use LLMs and other ML models to do this stuff.16 However, there are limits to how effective the tools can be at scale. Even Google, who has been working on Knowledge Graphs at scale and throws loads of money at the problem still occasionally gets things wrong.
Here’s the output of one of the knowledge graph creation tools that’s relatively user-friendly, Knowledge Graph Builder, which is a rather nifty Google Collab tool you can run on your own. It automates the process of creating a knowledge graph from Wikipedia’s knowledge base.17 Another extremely popular (but more technically complex) mechanism is to use a graph data management system like Neo4j. If you’re really into LangChain this implementation also looks rather promising.
In the example below, if I start with ‘Napoleon’ and give it some context about the OG Napoleon (e.g., French Revolution, Napoleon Bonaparte), the builder can create a knowledge graph from that semantic information. However, as you can see below, it quickly goes off the rails, at least if I was hoping to use this to create a graph only related to Napoleon Bonaparte, and not, say, other historical events or related themes(the Ancien Regime, France generally, or the Euro).
A heavily tweaked example of an auto-generated KG, based on the starting term of Napoleon. The connection to the Euro is… an interesting choice.
Applying this to Data Protection
If you’re still here, through all of that, first off, thank you. Second, I’m sorry.
This whole post was my attempt to understand the Step 2 problem with LLMs and GPAI models, because IMHO, sorting out the Step 2 problem is critical to make Step 3 (deletion/RTBF) happen at all.
And unsurprisingly, while tools exist to do NER, NED, and knowledge graphs and the like, it all remains really hardto do well and outside of models with relatively discrete, manageable datasets. Here are just a few of the reasons I’ve identified:
Size: Large language models are … large. ChatGPT 3 (the last model that OpenAI provided training data on), was trained with almost 500 billion tokens. Meta’s latest behemoth, Llama 3.1 405B, was trained on a whopping 15 trillion tokens with 405 billion parameters.18 For context, the average 200 page novel is 90,000 words.19A token is roughly 3/4 a word, so that 90k novel is around 67,500 tokens (math folks, feel free to mock and point and correct me here). That means 15 trillion tokens is roughly 7,407,407 million books, which is roughly half the size of the British Library.
I spent a minute trying to get various AI models to render this in bookcases before I opted for the more concrete example of the British Library. Still, this is a reasonably decent approximation of what 15 trillion tokens in books might look like, assuming bookshelves held 300,000 books each and you’re not thinking about it too much.
Data Quality: Without armies of humans, its doubtful, if not completely impossible to guarantee accuracy, completeness, timeliness, and all the other critical aspects that must be factored in to meet data quality obligations under the GDPR, and soon, the AI Act. Remember, we’re talking about massive quantities of content, most of which is messy and unstructured datasets from websites, blogs, public-facing social media posts, Reddit threads, and all the other random stuff OpenAI et al., dig up from behind the couch cushions of the internet. And while tools exist to automate some of this, the tools themselves don’t meet human-level standards, and often miss a lot, fail to understand all contextual clues, and still require human review.
Accuracy: This aspect of accuracy is a bit different to the data quality consideration I noted above. Here, I’m referring to accurate entity disambiguation, which is crucial for complying with data protection rights.Misidentifying an entity could lead to incorrect data deletion or modification, potentially violating data protection laws, and even impacting other fundamental human rights, as well as autonomy and choice.
It’s one thing for OpenAI to delete my account data. There’s only one associated account for me in database. But correctly generating a knowledge graph that identifies me across all collected training data is a much harder task. To borrow a line from the immortal words of the Notorious B.I.G., ‘Mo’ data, mo’ problems.’
Access: To achieve Step 2 at all requires access to the trainingdata in the first place. There’s no way to apply NER or NED techniques, or to derive meaningful entity linkages and knowledge graphs unless you’ve got access to the training and fine-tuning data.20 And by the looks of it, I’m doubtful that OpenAI, Google, Meta or Perplexity bothered with that step before releasing their LLMs into the wild.
This puts deployers of AI systems in a rather precarious spot. While the big boy GPAI model developers could build in better systems to resolve, disambiguate, and properly link Napoleon Bonaparte from Napoleon Dynamite, this isn’t really an achievable goal for downstream deployers of AI systems reliant on those models. Yet, they’re still bound to comply with all the same data protection obligations, including facilitating data subject rights.
The Hamburg DPA’s Opinion
I would be remiss if I didn’t mention that the Hamburg data protection authority (DPA) recently threw a spanner in the works regarding the question ‘Do LLMs store/process personal data’. In their ‘Discussion Paper on Large Language Models and Personal Data’, the DPA’s central thesis is that since LLM/GPAI models like Gemini 1.5 or Llama 3.1, or GPT4o only store tokens/embeddings and the relationships between those tokens, these tokens/embeddings are not personal data, and are therefore outside the scope of the GDPR.21 Here’s the DPA’s analysis:
Unlike the identifiers addressed in CJEU case law, which directly link to specific individuals, neither individual tokens nor their embeddings in LLMs contain such information about natural persons from the training dataset. Therefore, according to the standards set by CJEU jurisprudence, the question of whether personal data is stored in LLMs does not depend on the means available to a potential controller. In LLMs, the stored information already lacks the necessary direct, targeted association to individuals that characterizes personal data in CJEU jurisprudence: the information "relating" to a natural person. (p. 6)
Nor is the storage question affected by different privacy attacks on LLM systems which may expose personal data, including model inversion and membership inference attacks,22 principally because the attacks themselves are complicated, often illegal, and may require access to some or all of the training data.23
The Hamburg DPA was careful to note however, that while this absolved model developers of data subject obligations (access, rectification, deletion), that same comfort isn’t available to deployers of AI systems (read: every controller using ChatGPT / Perplexity / Gemini for downstream uses):
Organizations must ensure GDPR compliance when processing personal data. As LLMs don't store personal data, they can't be the direct subject of data subject rights under articles 12 et seq. GDPR. However, when an AI system processes personal data, particularly in its output or database queries, the controller must fulfill data subject rights. (p. 9, emphasis added, internal citations removed)
To do this, a company or public authority using a third-party LLM must ensure (via contract or through other means not explored) that the provider can, amongst other things, fulfill data subject rights. The thing is, I’m not sure contract will save the day here. Fundamentally, a controller making use of a third party LLM has no access to the training data. Nor will most controllers have much bargaining power to compel the likes of OpenAI, Meta, Google, or Anthropic to start doing the hard work of identifying, disambiguating, and linking entities to ensure an ongoing, timely, and accurate representation of an individual.
Even if training data is off the table, the Hamburg proposal assumes that deployers can in some way provide ‘output or database queries’ and fulfill data subject rights requests, but they provide no elaboration on how that can be done if… say it with me now … the deployer doesn’t have access to model training data, or a meaningful way to get OpenAI/Google/Meta to provide it.
Some Final Thoughts
As I see it, and I’ll be arguing in subsequent posts, I think we’ve got a legal Sophie’s Choice problem here. As I see it, there are three potential outcomes that will be painful indeed.
Legal change: The law changes and evolves to address non-deterministic systems like GPAI/LLMs. This is problematic for data subjects, and creates a two-tiered system in the law. And given the track record of major LLM providers, I’m not sure it’s ideal.
LLMs are banned: LLMs as a concept cease to be a thing. Regulators and governments simply do not allow massively large models like ChatGPT, Gemini, Claude, or Llama 3.1 to exist. Perhaps they’re replaced with smaller, more domain-specific models. Or perhaps the entire concept of generative AI goes away. I’m sure a number of people would be elated with this outcome, but I’m not sure it represents a likely option. Nation states have a pretty bad track record at doing things for the collective good, and this is a bit like nuclear weapons — it needs to be an all-or-nothing proposition.
We improve the entity disambiguation/linking problem: Which is to say, we get better at helping GPAI models to disambiguate and link to the right Napoleon. This seems possible, but I’m not sure it would be a good thing for the world. Let’s assume OpenAI or Google or Meta throw thousands of engineers at the problem, and they develop a near-perfect NED / entity linking / knowledge graph pipeline. Imagine, if you will, a 15-trillion token knowledge graph — not a database, per se, but structured in a way that was filing-system-adjacent. Accurate enough to paint precise pictures of everyone — or at least everyone whose data is in the training set.
In some respects, this would create a bigger problem for everyone. If we think that Google and Meta and the like know everything about us now, imagine how much more they would know with an accurate and precise knowledge graph of each and every one of us. Imagine the gold mine of data, all tightly and accurately linked and interconnected on each one of us, centralized, and accessible to prying commercial, governmental, and adversarial eyes.
If Google or Meta were able to harness what they’ve also collected from all the unstructured data they’ve used to train Gemini, and the tools for disambiguation and entity linking were improved, our ability to be private online in any capacity would cease to be a thing.
Look, I don’t have an answer to this question. I’m still trying to puzzle it all out. But like the Hamburg DPA, I’m hoping that this perhaps kicks off a discussion about what it means to comply with laws that can no longer easily be applied to the weird technical mess we’ve gotten ourselves into — at least not without some hard choices being made.
OpenAI also has this thing called ‘Memory’ that allows ChatGPT to remember things you discuss. It is not clear to me whether the memory is really just storing custom instructions in a database (in OpenAI’s case, Azure CosmosDB & PostGresDB), or if this is more like training data stored as vector embeddings. To me it looks more like the former. https://help.openai.com/en/articles/8590148-memory-faq#h_50152d864e
My exceedingly patient husband (AKA, Husbot) went to school to study advanced mathy things, and has told me repeatedly that if a paper can’t explain with words what it’s about and has to resort to exotic, novel or overly opaque math equations, they are practicing ‘abuse of notation’.
Which isn’t technically defined in the AI Act, but Recital 97 offers a good definition of sorts:
The notion of general-purpose AI models should be clearly defined and set apart from the notion of AI systems to enable legal certainty. The definition should be based on the key functional characteristics of a general-purpose AI model, in particular the generality and the capability to competently perform a wide range of distinct tasks. These models are typically trained on large amounts of data, through various methods, such as self-supervised, unsupervised or reinforcement learning. General-purpose AI models may be placed on the market in various ways, including through libraries, application programming interfaces (APIs), as direct download, or as physical copy. These models may be further modified or fine-tuned into new models. Although AI models are essential components of AI systems, they do not constitute AI systems on their own. AI models require the addition of further components, such as for example a user interface, to become AI systems. AI models are typically integrated into and form part of AI systems. … When the provider of a general-purpose AI model integrates an own model into its own AI system that is made available on the market or put into service, that model should be considered to be placed on the market and, therefore, the obligations in this Regulation for models should continue to apply in addition to those for AI systems. …
The definition for AI System is found in Article 3(1):
AI system‘ means a machine-based system that is designed to operate with varying levels of autonomy and that may exhibit adaptiveness after deployment, and that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments;
While both appear together in Article 17 GDPR, strictly speaking, erasure requires the controller to actually delete the record or information from a database or filing system, while the RTBF is more akin to suppression – the record still exists, but any links or breadcrumbs to the information related to the person wishing to be forgotten are hidden or erased.
This Regulation does not seek to affect the application of existing Union law governing the processing of personal data, including the tasks and powers of the independent supervisory authorities competent to monitor compliance with those instruments. It also does not affect the obligations of providers and deployers of AI systems in their role as data controllers or processors stemming from Union or national law on the protection of personal data in so far as the design, the development or the use of AI systems involves the processing of personal data. It is also appropriate to clarify that data subjects continue to enjoy all the rights and guarantees awarded to them by such Union law.”
See also: Article 2(7) (Scope); Annex V (EU Declaration of Conformity); Article 59(3) (AI sandboxes); Article 60(4(i) (requirements to honor consent, deletion for testing in real-world situations).
I need to stop and take a moment to explain how amazingly helpful my growing LinkedIn network has been. It’s been easy to wander down rat warrens of research and to bang my head against the wall trying to stubbornly figure it all out. When I’ve gotten really stuck, I’ve found that at least a few people in my network of brilliant contacts can usually un-block me and get me back on course. Say what you will about LinkedIn’s many faults, it’s one of the best resources I’ve found for actually getting answers to complex questions in this area from legit experts in the field.
Technically, this NER only generates MSIC, PER, & LOC. For purposes of this explainer, I tweaked the outputs for ‘French Revolution’ and ‘Napoleonic Wars’ to list as EVN instead.
NLTK is a python library that does a number of cool things, including chunking, which is something I used early on when I was trying to develop a process for summarizing cases.
Within the different NER/NEE frameworks, you can have wide variance between semantic entity classification, which makes things… interesting. In other words, if you try to run the same query in a different NER classifier, don’t be surprised if you get different outputs.
See for example: J. Hoffart, M. Amir Yosef, et al, “Robust Disambiguation of Named Entities in Text,” Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pages 782–792, Edinburgh, Scotland, UK, July 27–31, 2011. c 2011 Association for Computational Linguistics at: https://aclanthology.org/D11-1072.pdf.
OpenAI has even tinkered with entity disambiguation in earlier versions of its models. “Discovering types for entity disambiguation”, OpenAI, 2018-02-07, at: https://openai.com/index/discovering-types-for-entity-disambiguation/. For the hardcore nerds, there’s also an ArXiv paper included that goes into more of the algorithmic nerdery.
Unsurprisingly, the OpenAI paper uses a relatively discrete dataset (Wikipedia data), and describes an automated means for tagging and identifying whether a word (like jaguar) belongs to a defined entity type (e.g., animal, car, something else) based on context. They don’t refer to this as NER/NED, but I’m pretty sure that’s what they’re getting at. The point of it all this to map text to some specific named entity or ground truth.
S. Pan, L. Luo, et. al., “Unifying Large Language Models and Knowledge Graphs: A Roadmap. arXiv preprint arXiv:2306.08302v2. at: https://arxiv.org/abs/2306.08302; S. Liu, Y. Fang, “Use Large Language Models for Named Entity Disambiguation in Academic Knowledge Graphs,” Proceedings of the 2023 3rd International Conference on Education, Information Management and Service Science (EIMSS 2023), Atlantis Highlights in Computer Sciences 16, at: https://doi.org/10.2991/978-94-6463-264-4_79.
If you’re a researcher in this area, or more clueful on this subject, I am happy to be proven wrong. I suppose there’s the possibility of applying a limited NER/NED/EL approach to fine-tuned content added after the initial model training step, but I haven’t seen much discussion on this point.
Model inversion and membership inference attacks are two types of adversarial attacks which deliberately try to manipulate AI systems into sharing personal or other sensitive data by introducing carefully crafted inputs or queries or by comparing training data. Say a a data controller is given access to an earlier training set (A), but is not given access to more recent training data (B). By crafting specific queries, the controller might be able to infer what’s in training set B, by comparing the outputs to what it knows is in training set A.
A membership inference attack is where an attacker using specialized prompts or other techniques, infers whether a particular subset of data was used for training, particularly about an individual or an image. See: M. Veale, R. Binns, L. Edwards. “Algorithms that remember: model inversion attacks and data protection law.” Phil. Trans. R. Soc. A 376: 20180083. at: http://dx.doi.org/10.1098/rsta.2018.0083; N. Carlini, et al., “Extracting Training Data from Large Language Models,” 30th USENIX Security Symposium at: https://www.usenix.org/system/files/sec21-carlini-extracting.pdf; M. Chen, Z. Zhang, et al, “When Machine Unlearning Jeopardizes Privacy.” In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS ’21), November 15–19, 2021, at: https://dl.acm.org/doi/epdf/10.1145/3460120.3484756.
Hey, great read as always. Your 'needle' analogy makes total sense. Finding individual data in an LLM is like spotting a rare plant in a huge forest. Such a tough problem, Carey. Keep up the excelent work.
This is amazing work Carey! I didn’t realise how complicated locating the requisite personal data in a deletion request could be for LLMs (definitely does not look like something that is easily scalable so as to handle multiple requests). I thought the more difficult part would be the retraining/unlearning that comes after (or maybe that bit is even more tricky). Looking forward to your other posts on this issue.






, letters and syntax.")

, all seem to assume access to the training data, and specific set of data to look for (e.g. a name or a number) to isolate/remove from the training data (what I'm calling Step 1). Does anyone have any papers or sources that deal with how to answer the Step 1 problem in the context of a large training dataset (say OpenAI scale), particularly where you want to only target some subset of data (e. g., a specific individual -- Carey Lening the data protection consultant, not other Carey Lening's)?")
")
")
")
")
 but then quickly goes off the rails.")


Hey, great read as always. Your 'needle' analogy makes total sense. Finding individual data in an LLM is like spotting a rare plant in a huge forest. Such a tough problem, Carey. Keep up the excelent work.
This is amazing work Carey! I didn’t realise how complicated locating the requisite personal data in a deletion request could be for LLMs (definitely does not look like something that is easily scalable so as to handle multiple requests). I thought the more difficult part would be the retraining/unlearning that comes after (or maybe that bit is even more tricky). Looking forward to your other posts on this issue.